# Audio Embedding with Neural Network Fingerprint
*Author: [Jael Gu](https://github.com/jaelgu)*
## Description
The audio embedding operator converts an input audio into a dense vector which can be used to represent the audio clip's semantics.
Each vector represents for an audio clip with a fixed length of around 1s.
This operator generates audio embeddings with fingerprinting method introduced by [Neural Audio Fingerprint](https://arxiv.org/abs/2010.11910).
The model is implemented in Pytorch.
We've also trained the nnfp model with [FMA dataset](https://github.com/mdeff/fma) (& some noise audio) and shared weights in this operator.
The nnfp operator is suitable for audio fingerprinting.
## Code Example
Generate embeddings for the audio "test.wav".
*Write the pipeline in simplified style*:
```python
import towhee
(
towhee.glob('test.wav')
.audio_decode.ffmpeg()
.runas_op(func=lambda x:[y[0] for y in x])
.audio_embedding.nnfp() # use default model
.show()
)
```
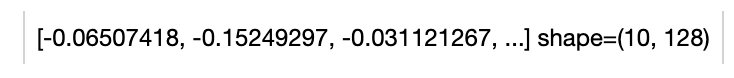 *Write a same pipeline with explicit inputs/outputs name specifications:*
```python
import towhee
(
towhee.glob['path']('test.wav')
.audio_decode.ffmpeg['path', 'frames']()
.runas_op['frames', 'frames'](func=lambda x:[y[0] for y in x])
.audio_embedding.nnfp['frames', 'vecs']()
.select['path', 'vecs']()
.show()
)
```
*Write a same pipeline with explicit inputs/outputs name specifications:*
```python
import towhee
(
towhee.glob['path']('test.wav')
.audio_decode.ffmpeg['path', 'frames']()
.runas_op['frames', 'frames'](func=lambda x:[y[0] for y in x])
.audio_embedding.nnfp['frames', 'vecs']()
.select['path', 'vecs']()
.show()
)
```

## Factory Constructor
Create the operator via the following factory method
***audio_embedding.nnfp(params=None, model_path=None, framework='pytorch')***
**Parameters:**
*params: dict*
A dictionary of model parameters. If None, it will use default parameters to create model.
*model_path: str*
The path to model. If None, it will load default model weights.
When the path ends with '.onnx', the operator will use onnx inference.
*framework: str*
The framework of model implementation.
Default value is "pytorch" since the model is implemented in Pytorch.
## Interface
An audio embedding operator generates vectors in numpy.ndarray given towhee audio frames.
***\_\_call\_\_(data)***
**Parameters:**
*data: List[towhee.types.audio_frame.AudioFrame]*
Input audio data is a list of towhee audio frames.
The audio input should be at least 1s.
**Returns**:
*numpy.ndarray*
Audio embeddings in shape (num_clips, 128).
Each embedding stands for features of an audio clip with length of 1s.
***save_model(format='pytorch', path='default')***
**Parameters:**
*format: str*
Format used to save model, defaults to 'pytorch'.
Accepted formats: 'pytorch', 'torchscript, 'onnx', 'tensorrt' (in progress)
*path: str*
Path to save model, defaults to 'default'.
The default path is under 'saved' in the same directory of operator cache.
```python
from towhee import ops
op = ops.audio_embedding.nnfp(device='cpu').get_op()
op.save_model('onnx', 'test.onnx')
```
PosixPath('/Home/.towhee/operators/audio-embedding/nnfp/main/test.onnx')