
copied
Readme
Files and versions
Updated 4 years ago
audio-embedding
Audio Embedding with Neural Network Fingerprint
Author: Jael Gu
Description
The audio embedding operator converts an input audio into a dense vector which can be used to represent the audio clip's semantics. Each vector represents for an audio clip with a fixed length of around 1s. This operator generates audio embeddings with fingerprinting method introduced by Neural Audio Fingerprint. The model is implemented in Pytorch. We've also trained the nnfp model with FMA dataset (& some noise audio) and shared weights in this operator. The nnfp operator is suitable for audio fingerprinting.
Code Example
Generate embeddings for the audio "test.wav".
Write the pipeline in simplified style:
import towhee
(
towhee.glob('test.wav')
.audio_decode.ffmpeg()
.runas_op(func=lambda x:[y[0] for y in x])
.audio_embedding.nnfp() # use default model
.show()
)
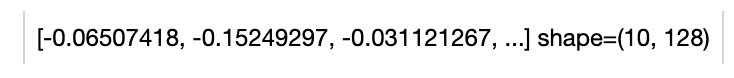
Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
(
towhee.glob['path']('test.wav')
.audio_decode.ffmpeg['path', 'frames']()
.runas_op['frames', 'frames'](func=lambda x:[y[0] for y in x])
.audio_embedding.nnfp['frames', 'vecs']()
.select['path', 'vecs']()
.show()
)

Factory Constructor
Create the operator via the following factory method
audio_embedding.nnfp(params=None, checkpoint_path=None, framework='pytorch')
Parameters:
params: dict
A dictionary of model parameters. If None, it will use default parameters to create model.
checkpoint_path: str
The path to model weights. If None, it will load default model weights.
framework: str
The framework of model implementation. Default value is "pytorch" since the model is implemented in Pytorch.
Interface
An audio embedding operator generates vectors in numpy.ndarray given towhee audio frames.
Parameters:
data: List[towhee.types.audio_frame.AudioFrame]
Input audio data is a list of towhee audio frames. The audio input should be at least 1s.
Returns:
numpy.ndarray
Audio embeddings in shape (num_clips, 128). Each embedding stands for features of an audio clip with length of 1s.
|
| 6 Commits | ||
|---|---|---|---|
 saved_model
saved_model
|
4 years ago | ||
 .gitattributes
.gitattributes
|
1.1 KiB
|
4 years ago | |
|
README.md
|
2.4 KiB
|
4 years ago | |
|
__init__.py
|
692 B
|
4 years ago | |
|
configs.py
|
1.0 KiB
|
4 years ago | |
|
nn_fingerprint.py
|
7.0 KiB
|
4 years ago | |
|
requirements.txt
|
47 B
|
4 years ago | |
|
result1.png
|
3.8 KiB
|
4 years ago | |
|
result2.png
|
5.9 KiB

|
4 years ago | |
|
test.py
|
1014 B
|
4 years ago | |
{kind=link}
{kind=link}