diff --git a/README.md b/README.md
index cfb1ee8..f72af4a 100644
--- a/README.md
+++ b/README.md
@@ -1,2 +1,107 @@
-# blip
+# Image-Text Retrieval Embdding with BLIP
+
+*author: David Wang*
+
+
+
+
+
+
+## Description
+
+This operator extracts features for image or text with [BLIP](https://arxiv.org/abs/2201.12086) which can generate embeddings for text and image by jointly training an image encoder and text encoder to maximize the cosine similarity. This is a adaptation from [salesforce/BLIP](https://github.com/salesforce/BLIP).
+
+
+
+
+
+## Code Example
+
+Load an image from path './teddy.jpg' to generate an image embedding.
+
+Read the text 'A teddybear on a skateboard in Times Square.' to generate an text embedding.
+
+ *Write the pipeline in simplified style*:
+
+```python
+import towhee
+
+towhee.glob('./teddy.jpg') \
+ .image_decode() \
+ .image_text_embedding.blip(model_name='blip_base', modality='image') \
+ .show()
+
+towhee.dc(["A teddybear on a skateboard in Times Square."]) \
+ .image_text_embedding.blip(model_name='blip_base', modality='text') \
+ .show()
+```
+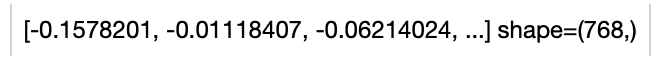 +
+ +
+*Write a same pipeline with explicit inputs/outputs name specifications:*
+
+```python
+import towhee
+
+towhee.glob['path']('./teddy.jpg') \
+ .image_decode['path', 'img']() \
+ .image_text_embedding.blip['img', 'vec'](model_name='blip_base', modality='image') \
+ .select['img', 'vec']() \
+ .show()
+
+towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
+ .image_text_embedding.blip['text','vec'](model_name='blip_base', modality='text') \
+ .select['text', 'vec']() \
+ .show()
+```
+
+
+*Write a same pipeline with explicit inputs/outputs name specifications:*
+
+```python
+import towhee
+
+towhee.glob['path']('./teddy.jpg') \
+ .image_decode['path', 'img']() \
+ .image_text_embedding.blip['img', 'vec'](model_name='blip_base', modality='image') \
+ .select['img', 'vec']() \
+ .show()
+
+towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
+ .image_text_embedding.blip['text','vec'](model_name='blip_base', modality='text') \
+ .select['text', 'vec']() \
+ .show()
+```
+ +
+ +
+
+
+
+
+
+
+
+
+## Factory Constructor
+
+Create the operator via the following factory method
+
+***blip(model_name, modality)***
+
+**Parameters:**
+
+ ***model_name:*** *str*
+
+ The model name of BLIP. Supported model names:
+- blip_base
+
+
+ ***modality:*** *str*
+
+ Which modality(*image* or *text*) is used to generate the embedding.
+
+
+
+
+
+## Interface
+
+An image-text embedding operator takes a [towhee image](link/to/towhee/image/api/doc) or string as input and generate an embedding in ndarray.
+
+
+**Parameters:**
+
+ ***data:*** *towhee.types.Image (a sub-class of numpy.ndarray)* or *str*
+
+ The data (image or text based on specified modality) to generate embedding.
+
+
+
+**Returns:** *numpy.ndarray*
+
+ The data embedding extracted by model.
+
+
+
+
diff --git a/__init__.py b/__init__.py
new file mode 100644
index 0000000..3a4024d
--- /dev/null
+++ b/__init__.py
@@ -0,0 +1,19 @@
+# Copyright 2021 Zilliz. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .blip import Blip
+
+
+def blip(model_name: str, modality: str):
+ return Blip(model_name, modality)
diff --git a/blip.py b/blip.py
new file mode 100644
index 0000000..b58066a
--- /dev/null
+++ b/blip.py
@@ -0,0 +1,72 @@
+# Copyright 2021 Zilliz. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+from pathlib import Path
+
+import torch
+from torchvision import transforms
+from torchvision.transforms.functional import InterpolationMode
+
+from towhee import register
+from towhee.operator.base import NNOperator, OperatorFlag
+from towhee.types.arg import arg, to_image_color
+from towhee.types.image_utils import from_pil, to_pil
+
+@register(output_schema=['vec'])
+class Blip(NNOperator):
+ """
+ BLIP multi-modal embedding operator
+ """
+ def __init__(self, model_name: str):
+ super().__init__()
+ sys.path.append(str(Path(__file__).parent))
+ from models.blip import blip_decoder
+ image_size = 384
+ model_url = self._configs()[model_name]['weights']
+ self.model = blip_decoder(pretrained=model_url, image_size=image_size, vit='base')
+
+ self._modality = modality
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ self.model.to(self.device)
+ self.model.eval()
+
+ self.tfms = transforms.Compose([
+ transforms.Resize((image_size,image_size),interpolation=InterpolationMode.BICUBIC),
+ transforms.ToTensor(),
+ transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
+ ])
+
+ @arg(1, to_image_color('RGB'))
+ def __call__(self, data:):
+ vec = self._inference_from_image(data)
+ return vec
+
+ @arg(1, to_image_color('RGB'))
+ def _inference_from_image(self, img):
+ img = self._preprocess(img)
+ caption = model.generate(img, sample=False, num_beams=3, max_length=20, min_length=5)
+ return caption[0]
+
+ def _preprocess(self, img):
+ img = to_pil(img)
+ processed_img = self.tfms(img).unsqueeze(0).to(self.device)
+ return processed_img
+
+ def _configs(self):
+ config = {}
+ config['blip_base'] = {}
+ config['blip_base']['weights'] = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_capfilt_large.pth'
+ return config
+
diff --git a/configs/med_config.json b/configs/med_config.json
new file mode 100644
index 0000000..d9031d2
--- /dev/null
+++ b/configs/med_config.json
@@ -0,0 +1,22 @@
+{
+ "architectures": [
+ "BertModel"
+ ],
+ "attention_probs_dropout_prob": 0.1,
+ "hidden_act": "gelu",
+ "hidden_dropout_prob": 0.1,
+ "hidden_size": 768,
+ "initializer_range": 0.02,
+ "intermediate_size": 3072,
+ "layer_norm_eps": 1e-12,
+ "max_position_embeddings": 512,
+ "model_type": "bert",
+ "num_attention_heads": 12,
+ "num_hidden_layers": 12,
+ "pad_token_id": 0,
+ "type_vocab_size": 2,
+ "vocab_size": 30524,
+ "encoder_width": 768,
+ "add_cross_attention": true
+}
+
diff --git a/models/__pycache__/blip.cpython-38.pyc b/models/__pycache__/blip.cpython-38.pyc
new file mode 100644
index 0000000..c413bad
Binary files /dev/null and b/models/__pycache__/blip.cpython-38.pyc differ
diff --git a/models/__pycache__/med.cpython-38.pyc b/models/__pycache__/med.cpython-38.pyc
new file mode 100644
index 0000000..e177a3b
Binary files /dev/null and b/models/__pycache__/med.cpython-38.pyc differ
diff --git a/models/__pycache__/vit.cpython-38.pyc b/models/__pycache__/vit.cpython-38.pyc
new file mode 100644
index 0000000..1459618
Binary files /dev/null and b/models/__pycache__/vit.cpython-38.pyc differ
diff --git a/models/blip.py b/models/blip.py
new file mode 100644
index 0000000..5d3619f
--- /dev/null
+++ b/models/blip.py
@@ -0,0 +1,240 @@
+'''
+ * Copyright (c) 2022, salesforce.com, inc.
+ * All rights reserved.
+ * SPDX-License-Identifier: BSD-3-Clause
+ * For full license text, see LICENSE.txt file in the repo root or https://opensource.org/licenses/BSD-3-Clause
+ * By Junnan Li
+'''
+import warnings
+warnings.filterwarnings("ignore")
+
+from models.vit import VisionTransformer, interpolate_pos_embed
+from models.med import BertConfig, BertModel, BertLMHeadModel
+from transformers import BertTokenizer
+
+import torch
+from torch import nn
+from pathlib import Path
+import torch.nn.functional as F
+
+import os
+from urllib.parse import urlparse
+from timm.models.hub import download_cached_file
+
+class BLIP_Base(nn.Module):
+ def __init__(self,
+ med_config = 'configs/med_config.json',
+ image_size = 224,
+ vit = 'base',
+ vit_grad_ckpt = False,
+ vit_ckpt_layer = 0,
+ ):
+ """
+ Args:
+ med_config (str): path for the mixture of encoder-decoder model's configuration file
+ image_size (int): input image size
+ vit (str): model size of vision transformer
+ """
+ super().__init__()
+ dirpath = str(Path(__file__).parent.parent)
+ med_config = dirpath + '/' + med_config
+ self.visual_encoder, vision_width = create_vit(vit,image_size, vit_grad_ckpt, vit_ckpt_layer)
+ self.tokenizer = init_tokenizer()
+ med_config = BertConfig.from_json_file(med_config)
+ med_config.encoder_width = vision_width
+ self.text_encoder = BertModel(config=med_config, add_pooling_layer=False)
+
+
+ def forward(self, image, caption, mode, device):
+
+ assert mode in ['image', 'text', 'multimodal'], "mode parameter must be image, text, or multimodal"
+ text = self.tokenizer(caption, return_tensors="pt").to(device)
+
+ if mode=='image':
+ # return image features
+ image_embeds = self.visual_encoder(image)
+ return image_embeds
+
+ elif mode=='text':
+ # return text features
+ text_output = self.text_encoder(text.input_ids, attention_mask = text.attention_mask,
+ return_dict = True, mode = 'text')
+ return text_output.last_hidden_state
+
+ elif mode=='multimodal':
+ # return multimodel features
+ image_embeds = self.visual_encoder(image)
+ image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(device)
+
+ text.input_ids[:,0] = self.tokenizer.enc_token_id
+ output = self.text_encoder(text.input_ids,
+ attention_mask = text.attention_mask,
+ encoder_hidden_states = image_embeds,
+ encoder_attention_mask = image_atts,
+ return_dict = True,
+ )
+ return output.last_hidden_state
+
+
+
+class BLIP_Decoder(nn.Module):
+ def __init__(self,
+ med_config = 'configs/med_config.json',
+ image_size = 384,
+ vit = 'base',
+ vit_grad_ckpt = False,
+ vit_ckpt_layer = 0,
+ prompt = 'a picture of ',
+ ):
+ """
+ Args:
+ med_config (str): path for the mixture of encoder-decoder model's configuration file
+ image_size (int): input image size
+ vit (str): model size of vision transformer
+ """
+ super().__init__()
+
+ self.visual_encoder, vision_width = create_vit(vit,image_size, vit_grad_ckpt, vit_ckpt_layer)
+ self.tokenizer = init_tokenizer()
+ med_config = BertConfig.from_json_file(med_config)
+ med_config.encoder_width = vision_width
+ self.text_decoder = BertLMHeadModel(config=med_config)
+
+ self.prompt = prompt
+ self.prompt_length = len(self.tokenizer(self.prompt).input_ids)-1
+
+
+ def forward(self, image, caption):
+
+ image_embeds = self.visual_encoder(image)
+ image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
+
+ text = self.tokenizer(caption, padding='longest', truncation=True, max_length=40, return_tensors="pt").to(image.device)
+
+ text.input_ids[:,0] = self.tokenizer.bos_token_id
+
+ decoder_targets = text.input_ids.masked_fill(text.input_ids == self.tokenizer.pad_token_id, -100)
+ decoder_targets[:,:self.prompt_length] = -100
+
+ decoder_output = self.text_decoder(text.input_ids,
+ attention_mask = text.attention_mask,
+ encoder_hidden_states = image_embeds,
+ encoder_attention_mask = image_atts,
+ labels = decoder_targets,
+ return_dict = True,
+ )
+ loss_lm = decoder_output.loss
+
+ return loss_lm
+
+ def generate(self, image, sample=False, num_beams=3, max_length=30, min_length=10, top_p=0.9, repetition_penalty=1.0):
+ image_embeds = self.visual_encoder(image)
+
+ if not sample:
+ image_embeds = image_embeds.repeat_interleave(num_beams,dim=0)
+
+ image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
+ model_kwargs = {"encoder_hidden_states": image_embeds, "encoder_attention_mask":image_atts}
+
+ prompt = [self.prompt] * image.size(0)
+ input_ids = self.tokenizer(prompt, return_tensors="pt").input_ids.to(image.device)
+ input_ids[:,0] = self.tokenizer.bos_token_id
+ input_ids = input_ids[:, :-1]
+
+ if sample:
+ #nucleus sampling
+ outputs = self.text_decoder.generate(input_ids=input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ do_sample=True,
+ top_p=top_p,
+ num_return_sequences=1,
+ eos_token_id=self.tokenizer.sep_token_id,
+ pad_token_id=self.tokenizer.pad_token_id,
+ repetition_penalty=1.1,
+ **model_kwargs)
+ else:
+ #beam search
+ outputs = self.text_decoder.generate(input_ids=input_ids,
+ max_length=max_length,
+ min_length=min_length,
+ num_beams=num_beams,
+ eos_token_id=self.tokenizer.sep_token_id,
+ pad_token_id=self.tokenizer.pad_token_id,
+ repetition_penalty=repetition_penalty,
+ **model_kwargs)
+
+ captions = []
+ for output in outputs:
+ caption = self.tokenizer.decode(output, skip_special_tokens=True)
+ captions.append(caption[len(self.prompt):])
+ return captions
+
+
+def blip_decoder(pretrained='',**kwargs):
+ model = BLIP_Decoder(**kwargs)
+ if pretrained:
+ model,msg = load_checkpoint(model,pretrained)
+ assert(len(msg.missing_keys)==0)
+ return model
+
+def blip_feature_extractor(pretrained='',**kwargs):
+ model = BLIP_Base(**kwargs)
+ if pretrained:
+ model,msg = load_checkpoint(model,pretrained)
+ assert(len(msg.missing_keys)==0)
+ return model
+
+def init_tokenizer():
+ tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
+ tokenizer.add_special_tokens({'bos_token':'[DEC]'})
+ tokenizer.add_special_tokens({'additional_special_tokens':['[ENC]']})
+ tokenizer.enc_token_id = tokenizer.additional_special_tokens_ids[0]
+ return tokenizer
+
+
+def create_vit(vit, image_size, use_grad_checkpointing=False, ckpt_layer=0, drop_path_rate=0):
+
+ assert vit in ['base', 'large'], "vit parameter must be base or large"
+ if vit=='base':
+ vision_width = 768
+ visual_encoder = VisionTransformer(img_size=image_size, patch_size=16, embed_dim=vision_width, depth=12,
+ num_heads=12, use_grad_checkpointing=use_grad_checkpointing, ckpt_layer=ckpt_layer,
+ drop_path_rate=0 or drop_path_rate
+ )
+ elif vit=='large':
+ vision_width = 1024
+ visual_encoder = VisionTransformer(img_size=image_size, patch_size=16, embed_dim=vision_width, depth=24,
+ num_heads=16, use_grad_checkpointing=use_grad_checkpointing, ckpt_layer=ckpt_layer,
+ drop_path_rate=0.1 or drop_path_rate
+ )
+ return visual_encoder, vision_width
+
+def is_url(url_or_filename):
+ parsed = urlparse(url_or_filename)
+ return parsed.scheme in ("http", "https")
+
+def load_checkpoint(model,url_or_filename):
+ if is_url(url_or_filename):
+ cached_file = download_cached_file(url_or_filename, check_hash=False, progress=True)
+ checkpoint = torch.load(cached_file, map_location='cpu')
+ elif os.path.isfile(url_or_filename):
+ checkpoint = torch.load(url_or_filename, map_location='cpu')
+ else:
+ raise RuntimeError('checkpoint url or path is invalid')
+
+ state_dict = checkpoint['model']
+
+ state_dict['visual_encoder.pos_embed'] = interpolate_pos_embed(state_dict['visual_encoder.pos_embed'],model.visual_encoder)
+ if 'visual_encoder_m.pos_embed' in model.state_dict().keys():
+ state_dict['visual_encoder_m.pos_embed'] = interpolate_pos_embed(state_dict['visual_encoder_m.pos_embed'],
+ model.visual_encoder_m)
+ for key in model.state_dict().keys():
+ if key in state_dict.keys():
+ if state_dict[key].shape!=model.state_dict()[key].shape:
+ del state_dict[key]
+
+ msg = model.load_state_dict(state_dict,strict=False)
+ print('load checkpoint from %s'%url_or_filename)
+ return model,msg
+
diff --git a/models/med.py b/models/med.py
new file mode 100644
index 0000000..7b00a35
--- /dev/null
+++ b/models/med.py
@@ -0,0 +1,955 @@
+'''
+ * Copyright (c) 2022, salesforce.com, inc.
+ * All rights reserved.
+ * SPDX-License-Identifier: BSD-3-Clause
+ * For full license text, see LICENSE.txt file in the repo root or https://opensource.org/licenses/BSD-3-Clause
+ * By Junnan Li
+ * Based on huggingface code base
+ * https://github.com/huggingface/transformers/blob/v4.15.0/src/transformers/models/bert
+'''
+
+import math
+import os
+import warnings
+from dataclasses import dataclass
+from typing import Optional, Tuple
+
+import torch
+from torch import Tensor, device, dtype, nn
+import torch.utils.checkpoint
+from torch import nn
+from torch.nn import CrossEntropyLoss
+import torch.nn.functional as F
+
+from transformers.activations import ACT2FN
+from transformers.file_utils import (
+ ModelOutput,
+)
+from transformers.modeling_outputs import (
+ BaseModelOutputWithPastAndCrossAttentions,
+ BaseModelOutputWithPoolingAndCrossAttentions,
+ CausalLMOutputWithCrossAttentions,
+ MaskedLMOutput,
+ MultipleChoiceModelOutput,
+ NextSentencePredictorOutput,
+ QuestionAnsweringModelOutput,
+ SequenceClassifierOutput,
+ TokenClassifierOutput,
+)
+from transformers.modeling_utils import (
+ PreTrainedModel,
+ apply_chunking_to_forward,
+ find_pruneable_heads_and_indices,
+ prune_linear_layer,
+)
+from transformers.utils import logging
+from transformers.models.bert.configuration_bert import BertConfig
+
+
+logger = logging.get_logger(__name__)
+
+
+class BertEmbeddings(nn.Module):
+ """Construct the embeddings from word and position embeddings."""
+
+ def __init__(self, config):
+ super().__init__()
+ self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)
+ self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)
+
+ # self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
+ # any TensorFlow checkpoint file
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ # position_ids (1, len position emb) is contiguous in memory and exported when serialized
+ self.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+
+ self.config = config
+
+ def forward(
+ self, input_ids=None, position_ids=None, inputs_embeds=None, past_key_values_length=0
+ ):
+ if input_ids is not None:
+ input_shape = input_ids.size()
+ else:
+ input_shape = inputs_embeds.size()[:-1]
+
+ seq_length = input_shape[1]
+
+ if position_ids is None:
+ position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length]
+
+ if inputs_embeds is None:
+ inputs_embeds = self.word_embeddings(input_ids)
+
+ embeddings = inputs_embeds
+
+ if self.position_embedding_type == "absolute":
+ position_embeddings = self.position_embeddings(position_ids)
+ embeddings += position_embeddings
+ embeddings = self.LayerNorm(embeddings)
+ embeddings = self.dropout(embeddings)
+ return embeddings
+
+
+class BertSelfAttention(nn.Module):
+ def __init__(self, config, is_cross_attention):
+ super().__init__()
+ self.config = config
+ if config.hidden_size % config.num_attention_heads != 0 and not hasattr(config, "embedding_size"):
+ raise ValueError(
+ "The hidden size (%d) is not a multiple of the number of attention "
+ "heads (%d)" % (config.hidden_size, config.num_attention_heads)
+ )
+
+ self.num_attention_heads = config.num_attention_heads
+ self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
+ self.all_head_size = self.num_attention_heads * self.attention_head_size
+
+ self.query = nn.Linear(config.hidden_size, self.all_head_size)
+ if is_cross_attention:
+ self.key = nn.Linear(config.encoder_width, self.all_head_size)
+ self.value = nn.Linear(config.encoder_width, self.all_head_size)
+ else:
+ self.key = nn.Linear(config.hidden_size, self.all_head_size)
+ self.value = nn.Linear(config.hidden_size, self.all_head_size)
+
+ self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
+ self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ self.max_position_embeddings = config.max_position_embeddings
+ self.distance_embedding = nn.Embedding(2 * config.max_position_embeddings - 1, self.attention_head_size)
+ self.save_attention = False
+
+ def save_attn_gradients(self, attn_gradients):
+ self.attn_gradients = attn_gradients
+
+ def get_attn_gradients(self):
+ return self.attn_gradients
+
+ def save_attention_map(self, attention_map):
+ self.attention_map = attention_map
+
+ def get_attention_map(self):
+ return self.attention_map
+
+ def transpose_for_scores(self, x):
+ new_x_shape = x.size()[:-1] + (self.num_attention_heads, self.attention_head_size)
+ x = x.view(*new_x_shape)
+ return x.permute(0, 2, 1, 3)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ ):
+ mixed_query_layer = self.query(hidden_states)
+
+ # If this is instantiated as a cross-attention module, the keys
+ # and values come from an encoder; the attention mask needs to be
+ # such that the encoder's padding tokens are not attended to.
+ is_cross_attention = encoder_hidden_states is not None
+
+ if is_cross_attention:
+ key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
+ value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
+ attention_mask = encoder_attention_mask
+ elif past_key_value is not None:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+ key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
+ value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
+ else:
+ key_layer = self.transpose_for_scores(self.key(hidden_states))
+ value_layer = self.transpose_for_scores(self.value(hidden_states))
+
+ query_layer = self.transpose_for_scores(mixed_query_layer)
+
+ past_key_value = (key_layer, value_layer)
+
+ # Take the dot product between "query" and "key" to get the raw attention scores.
+ attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
+
+ if self.position_embedding_type == "relative_key" or self.position_embedding_type == "relative_key_query":
+ seq_length = hidden_states.size()[1]
+ position_ids_l = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(-1, 1)
+ position_ids_r = torch.arange(seq_length, dtype=torch.long, device=hidden_states.device).view(1, -1)
+ distance = position_ids_l - position_ids_r
+ positional_embedding = self.distance_embedding(distance + self.max_position_embeddings - 1)
+ positional_embedding = positional_embedding.to(dtype=query_layer.dtype) # fp16 compatibility
+
+ if self.position_embedding_type == "relative_key":
+ relative_position_scores = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores
+ elif self.position_embedding_type == "relative_key_query":
+ relative_position_scores_query = torch.einsum("bhld,lrd->bhlr", query_layer, positional_embedding)
+ relative_position_scores_key = torch.einsum("bhrd,lrd->bhlr", key_layer, positional_embedding)
+ attention_scores = attention_scores + relative_position_scores_query + relative_position_scores_key
+
+ attention_scores = attention_scores / math.sqrt(self.attention_head_size)
+ if attention_mask is not None:
+ # Apply the attention mask is (precomputed for all layers in BertModel forward() function)
+ attention_scores = attention_scores + attention_mask
+
+ # Normalize the attention scores to probabilities.
+ attention_probs = nn.Softmax(dim=-1)(attention_scores)
+
+ if is_cross_attention and self.save_attention:
+ self.save_attention_map(attention_probs)
+ attention_probs.register_hook(self.save_attn_gradients)
+
+ # This is actually dropping out entire tokens to attend to, which might
+ # seem a bit unusual, but is taken from the original Transformer paper.
+ attention_probs_dropped = self.dropout(attention_probs)
+
+ # Mask heads if we want to
+ if head_mask is not None:
+ attention_probs_dropped = attention_probs_dropped * head_mask
+
+ context_layer = torch.matmul(attention_probs_dropped, value_layer)
+
+ context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
+ new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
+ context_layer = context_layer.view(*new_context_layer_shape)
+
+ outputs = (context_layer, attention_probs) if output_attentions else (context_layer,)
+
+ outputs = outputs + (past_key_value,)
+ return outputs
+
+
+class BertSelfOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states, input_tensor):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertAttention(nn.Module):
+ def __init__(self, config, is_cross_attention=False):
+ super().__init__()
+ self.self = BertSelfAttention(config, is_cross_attention)
+ self.output = BertSelfOutput(config)
+ self.pruned_heads = set()
+
+ def prune_heads(self, heads):
+ if len(heads) == 0:
+ return
+ heads, index = find_pruneable_heads_and_indices(
+ heads, self.self.num_attention_heads, self.self.attention_head_size, self.pruned_heads
+ )
+
+ # Prune linear layers
+ self.self.query = prune_linear_layer(self.self.query, index)
+ self.self.key = prune_linear_layer(self.self.key, index)
+ self.self.value = prune_linear_layer(self.self.value, index)
+ self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
+
+ # Update hyper params and store pruned heads
+ self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
+ self.self.all_head_size = self.self.attention_head_size * self.self.num_attention_heads
+ self.pruned_heads = self.pruned_heads.union(heads)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ ):
+ self_outputs = self.self(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ )
+ attention_output = self.output(self_outputs[0], hidden_states)
+ outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
+ return outputs
+
+
+class BertIntermediate(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
+ if isinstance(config.hidden_act, str):
+ self.intermediate_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.intermediate_act_fn = config.hidden_act
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.intermediate_act_fn(hidden_states)
+ return hidden_states
+
+
+class BertOutput(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+ self.dropout = nn.Dropout(config.hidden_dropout_prob)
+
+ def forward(self, hidden_states, input_tensor):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.dropout(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states + input_tensor)
+ return hidden_states
+
+
+class BertLayer(nn.Module):
+ def __init__(self, config, layer_num):
+ super().__init__()
+ self.config = config
+ self.chunk_size_feed_forward = config.chunk_size_feed_forward
+ self.seq_len_dim = 1
+ self.attention = BertAttention(config)
+ self.layer_num = layer_num
+ if self.config.add_cross_attention:
+ self.crossattention = BertAttention(config, is_cross_attention=self.config.add_cross_attention)
+ self.intermediate = BertIntermediate(config)
+ self.output = BertOutput(config)
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_value=None,
+ output_attentions=False,
+ mode=None,
+ ):
+ # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
+ self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
+ self_attention_outputs = self.attention(
+ hidden_states,
+ attention_mask,
+ head_mask,
+ output_attentions=output_attentions,
+ past_key_value=self_attn_past_key_value,
+ )
+ attention_output = self_attention_outputs[0]
+
+ outputs = self_attention_outputs[1:-1]
+ present_key_value = self_attention_outputs[-1]
+
+ if mode=='multimodal':
+ assert encoder_hidden_states is not None, "encoder_hidden_states must be given for cross-attention layers"
+
+ cross_attention_outputs = self.crossattention(
+ attention_output,
+ attention_mask,
+ head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ output_attentions=output_attentions,
+ )
+ attention_output = cross_attention_outputs[0]
+ outputs = outputs + cross_attention_outputs[1:-1] # add cross attentions if we output attention weights
+ layer_output = apply_chunking_to_forward(
+ self.feed_forward_chunk, self.chunk_size_feed_forward, self.seq_len_dim, attention_output
+ )
+ outputs = (layer_output,) + outputs
+
+ outputs = outputs + (present_key_value,)
+
+ return outputs
+
+ def feed_forward_chunk(self, attention_output):
+ intermediate_output = self.intermediate(attention_output)
+ layer_output = self.output(intermediate_output, attention_output)
+ return layer_output
+
+
+class BertEncoder(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.config = config
+ self.layer = nn.ModuleList([BertLayer(config,i) for i in range(config.num_hidden_layers)])
+ self.gradient_checkpointing = False
+
+ def forward(
+ self,
+ hidden_states,
+ attention_mask=None,
+ head_mask=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=False,
+ output_hidden_states=False,
+ return_dict=True,
+ mode='multimodal',
+ ):
+ all_hidden_states = () if output_hidden_states else None
+ all_self_attentions = () if output_attentions else None
+ all_cross_attentions = () if output_attentions and self.config.add_cross_attention else None
+
+ next_decoder_cache = () if use_cache else None
+
+ for i in range(self.config.num_hidden_layers):
+ layer_module = self.layer[i]
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ layer_head_mask = head_mask[i] if head_mask is not None else None
+ past_key_value = past_key_values[i] if past_key_values is not None else None
+
+ if self.gradient_checkpointing and self.training:
+
+ if use_cache:
+ logger.warn(
+ "`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
+ )
+ use_cache = False
+
+ def create_custom_forward(module):
+ def custom_forward(*inputs):
+ return module(*inputs, past_key_value, output_attentions)
+
+ return custom_forward
+
+ layer_outputs = torch.utils.checkpoint.checkpoint(
+ create_custom_forward(layer_module),
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ mode=mode,
+ )
+ else:
+ layer_outputs = layer_module(
+ hidden_states,
+ attention_mask,
+ layer_head_mask,
+ encoder_hidden_states,
+ encoder_attention_mask,
+ past_key_value,
+ output_attentions,
+ mode=mode,
+ )
+
+ hidden_states = layer_outputs[0]
+ if use_cache:
+ next_decoder_cache += (layer_outputs[-1],)
+ if output_attentions:
+ all_self_attentions = all_self_attentions + (layer_outputs[1],)
+
+ if output_hidden_states:
+ all_hidden_states = all_hidden_states + (hidden_states,)
+
+ if not return_dict:
+ return tuple(
+ v
+ for v in [
+ hidden_states,
+ next_decoder_cache,
+ all_hidden_states,
+ all_self_attentions,
+ all_cross_attentions,
+ ]
+ if v is not None
+ )
+ return BaseModelOutputWithPastAndCrossAttentions(
+ last_hidden_state=hidden_states,
+ past_key_values=next_decoder_cache,
+ hidden_states=all_hidden_states,
+ attentions=all_self_attentions,
+ cross_attentions=all_cross_attentions,
+ )
+
+
+class BertPooler(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ self.activation = nn.Tanh()
+
+ def forward(self, hidden_states):
+ # We "pool" the model by simply taking the hidden state corresponding
+ # to the first token.
+ first_token_tensor = hidden_states[:, 0]
+ pooled_output = self.dense(first_token_tensor)
+ pooled_output = self.activation(pooled_output)
+ return pooled_output
+
+
+class BertPredictionHeadTransform(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.dense = nn.Linear(config.hidden_size, config.hidden_size)
+ if isinstance(config.hidden_act, str):
+ self.transform_act_fn = ACT2FN[config.hidden_act]
+ else:
+ self.transform_act_fn = config.hidden_act
+ self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
+
+ def forward(self, hidden_states):
+ hidden_states = self.dense(hidden_states)
+ hidden_states = self.transform_act_fn(hidden_states)
+ hidden_states = self.LayerNorm(hidden_states)
+ return hidden_states
+
+
+class BertLMPredictionHead(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.transform = BertPredictionHeadTransform(config)
+
+ # The output weights are the same as the input embeddings, but there is
+ # an output-only bias for each token.
+ self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
+
+ self.bias = nn.Parameter(torch.zeros(config.vocab_size))
+
+ # Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
+ self.decoder.bias = self.bias
+
+ def forward(self, hidden_states):
+ hidden_states = self.transform(hidden_states)
+ hidden_states = self.decoder(hidden_states)
+ return hidden_states
+
+
+class BertOnlyMLMHead(nn.Module):
+ def __init__(self, config):
+ super().__init__()
+ self.predictions = BertLMPredictionHead(config)
+
+ def forward(self, sequence_output):
+ prediction_scores = self.predictions(sequence_output)
+ return prediction_scores
+
+
+class BertPreTrainedModel(PreTrainedModel):
+ """
+ An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
+ models.
+ """
+
+ config_class = BertConfig
+ base_model_prefix = "bert"
+ _keys_to_ignore_on_load_missing = [r"position_ids"]
+
+ def _init_weights(self, module):
+ """ Initialize the weights """
+ if isinstance(module, (nn.Linear, nn.Embedding)):
+ # Slightly different from the TF version which uses truncated_normal for initialization
+ # cf https://github.com/pytorch/pytorch/pull/5617
+ module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
+ elif isinstance(module, nn.LayerNorm):
+ module.bias.data.zero_()
+ module.weight.data.fill_(1.0)
+ if isinstance(module, nn.Linear) and module.bias is not None:
+ module.bias.data.zero_()
+
+
+class BertModel(BertPreTrainedModel):
+ """
+ The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
+ cross-attention is added between the self-attention layers, following the architecture described in `Attention is
+ all you need `__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
+ Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
+ argument and :obj:`add_cross_attention` set to :obj:`True`; an :obj:`encoder_hidden_states` is then expected as an
+ input to the forward pass.
+ """
+
+ def __init__(self, config, add_pooling_layer=True):
+ super().__init__(config)
+ self.config = config
+
+ self.embeddings = BertEmbeddings(config)
+
+ self.encoder = BertEncoder(config)
+
+ self.pooler = BertPooler(config) if add_pooling_layer else None
+
+ self.init_weights()
+
+
+ def get_input_embeddings(self):
+ return self.embeddings.word_embeddings
+
+ def set_input_embeddings(self, value):
+ self.embeddings.word_embeddings = value
+
+ def _prune_heads(self, heads_to_prune):
+ """
+ Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
+ class PreTrainedModel
+ """
+ for layer, heads in heads_to_prune.items():
+ self.encoder.layer[layer].attention.prune_heads(heads)
+
+
+ def get_extended_attention_mask(self, attention_mask: Tensor, input_shape: Tuple[int], device: device, is_decoder: bool) -> Tensor:
+ """
+ Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
+
+ Arguments:
+ attention_mask (:obj:`torch.Tensor`):
+ Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
+ input_shape (:obj:`Tuple[int]`):
+ The shape of the input to the model.
+ device: (:obj:`torch.device`):
+ The device of the input to the model.
+
+ Returns:
+ :obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
+ """
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ if attention_mask.dim() == 3:
+ extended_attention_mask = attention_mask[:, None, :, :]
+ elif attention_mask.dim() == 2:
+ # Provided a padding mask of dimensions [batch_size, seq_length]
+ # - if the model is a decoder, apply a causal mask in addition to the padding mask
+ # - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if is_decoder:
+ batch_size, seq_length = input_shape
+
+ seq_ids = torch.arange(seq_length, device=device)
+ causal_mask = seq_ids[None, None, :].repeat(batch_size, seq_length, 1) <= seq_ids[None, :, None]
+ # in case past_key_values are used we need to add a prefix ones mask to the causal mask
+ # causal and attention masks must have same type with pytorch version < 1.3
+ causal_mask = causal_mask.to(attention_mask.dtype)
+
+ if causal_mask.shape[1] < attention_mask.shape[1]:
+ prefix_seq_len = attention_mask.shape[1] - causal_mask.shape[1]
+ causal_mask = torch.cat(
+ [
+ torch.ones((batch_size, seq_length, prefix_seq_len), device=device, dtype=causal_mask.dtype),
+ causal_mask,
+ ],
+ axis=-1,
+ )
+
+ extended_attention_mask = causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
+ else:
+ extended_attention_mask = attention_mask[:, None, None, :]
+ else:
+ raise ValueError(
+ "Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(
+ input_shape, attention_mask.shape
+ )
+ )
+
+ # Since attention_mask is 1.0 for positions we want to attend and 0.0 for
+ # masked positions, this operation will create a tensor which is 0.0 for
+ # positions we want to attend and -10000.0 for masked positions.
+ # Since we are adding it to the raw scores before the softmax, this is
+ # effectively the same as removing these entirely.
+ extended_attention_mask = extended_attention_mask.to(dtype=self.dtype) # fp16 compatibility
+ extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
+ return extended_attention_mask
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ encoder_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ is_decoder=False,
+ mode='multimodal',
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ """
+ output_attentions = output_attentions if output_attentions is not None else self.config.output_attentions
+ output_hidden_states = (
+ output_hidden_states if output_hidden_states is not None else self.config.output_hidden_states
+ )
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+
+ if is_decoder:
+ use_cache = use_cache if use_cache is not None else self.config.use_cache
+ else:
+ use_cache = False
+
+ if input_ids is not None and inputs_embeds is not None:
+ raise ValueError("You cannot specify both input_ids and inputs_embeds at the same time")
+ elif input_ids is not None:
+ input_shape = input_ids.size()
+ batch_size, seq_length = input_shape
+ device = input_ids.device
+ elif inputs_embeds is not None:
+ input_shape = inputs_embeds.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = inputs_embeds.device
+ elif encoder_embeds is not None:
+ input_shape = encoder_embeds.size()[:-1]
+ batch_size, seq_length = input_shape
+ device = encoder_embeds.device
+ else:
+ raise ValueError("You have to specify either input_ids or inputs_embeds or encoder_embeds")
+
+ # past_key_values_length
+ past_key_values_length = past_key_values[0][0].shape[2] if past_key_values is not None else 0
+
+ if attention_mask is None:
+ attention_mask = torch.ones(((batch_size, seq_length + past_key_values_length)), device=device)
+
+ # We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
+ # ourselves in which case we just need to make it broadcastable to all heads.
+ extended_attention_mask: torch.Tensor = self.get_extended_attention_mask(attention_mask, input_shape,
+ device, is_decoder)
+
+ # If a 2D or 3D attention mask is provided for the cross-attention
+ # we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
+ if encoder_hidden_states is not None:
+ if type(encoder_hidden_states) == list:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states[0].size()
+ else:
+ encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states.size()
+ encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
+
+ if type(encoder_attention_mask) == list:
+ encoder_extended_attention_mask = [self.invert_attention_mask(mask) for mask in encoder_attention_mask]
+ elif encoder_attention_mask is None:
+ encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = self.invert_attention_mask(encoder_attention_mask)
+ else:
+ encoder_extended_attention_mask = None
+
+ # Prepare head mask if needed
+ # 1.0 in head_mask indicate we keep the head
+ # attention_probs has shape bsz x n_heads x N x N
+ # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
+ # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
+ head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
+
+ if encoder_embeds is None:
+ embedding_output = self.embeddings(
+ input_ids=input_ids,
+ position_ids=position_ids,
+ inputs_embeds=inputs_embeds,
+ past_key_values_length=past_key_values_length,
+ )
+ else:
+ embedding_output = encoder_embeds
+
+ encoder_outputs = self.encoder(
+ embedding_output,
+ attention_mask=extended_attention_mask,
+ head_mask=head_mask,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_extended_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ mode=mode,
+ )
+ sequence_output = encoder_outputs[0]
+ pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
+
+ if not return_dict:
+ return (sequence_output, pooled_output) + encoder_outputs[1:]
+
+ return BaseModelOutputWithPoolingAndCrossAttentions(
+ last_hidden_state=sequence_output,
+ pooler_output=pooled_output,
+ past_key_values=encoder_outputs.past_key_values,
+ hidden_states=encoder_outputs.hidden_states,
+ attentions=encoder_outputs.attentions,
+ cross_attentions=encoder_outputs.cross_attentions,
+ )
+
+
+
+class BertLMHeadModel(BertPreTrainedModel):
+
+ _keys_to_ignore_on_load_unexpected = [r"pooler"]
+ _keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
+
+ def __init__(self, config):
+ super().__init__(config)
+
+ self.bert = BertModel(config, add_pooling_layer=False)
+ self.cls = BertOnlyMLMHead(config)
+
+ self.init_weights()
+
+ def get_output_embeddings(self):
+ return self.cls.predictions.decoder
+
+ def set_output_embeddings(self, new_embeddings):
+ self.cls.predictions.decoder = new_embeddings
+
+ def forward(
+ self,
+ input_ids=None,
+ attention_mask=None,
+ position_ids=None,
+ head_mask=None,
+ inputs_embeds=None,
+ encoder_hidden_states=None,
+ encoder_attention_mask=None,
+ labels=None,
+ past_key_values=None,
+ use_cache=None,
+ output_attentions=None,
+ output_hidden_states=None,
+ return_dict=None,
+ return_logits=False,
+ is_decoder=True,
+ reduction='mean',
+ mode='multimodal',
+ ):
+ r"""
+ encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
+ Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
+ the model is configured as a decoder.
+ encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
+ the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
+ - 1 for tokens that are **not masked**,
+ - 0 for tokens that are **masked**.
+ labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
+ Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
+ ``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are
+ ignored (masked), the loss is only computed for the tokens with labels n ``[0, ..., config.vocab_size]``
+ past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
+ Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
+ If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
+ (those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
+ instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
+ use_cache (:obj:`bool`, `optional`):
+ If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
+ decoding (see :obj:`past_key_values`).
+ Returns:
+ Example::
+ >>> from transformers import BertTokenizer, BertLMHeadModel, BertConfig
+ >>> import torch
+ >>> tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
+ >>> config = BertConfig.from_pretrained("bert-base-cased")
+ >>> model = BertLMHeadModel.from_pretrained('bert-base-cased', config=config)
+ >>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
+ >>> outputs = model(**inputs)
+ >>> prediction_logits = outputs.logits
+ """
+ return_dict = return_dict if return_dict is not None else self.config.use_return_dict
+ if labels is not None:
+ use_cache = False
+
+ outputs = self.bert(
+ input_ids,
+ attention_mask=attention_mask,
+ position_ids=position_ids,
+ head_mask=head_mask,
+ inputs_embeds=inputs_embeds,
+ encoder_hidden_states=encoder_hidden_states,
+ encoder_attention_mask=encoder_attention_mask,
+ past_key_values=past_key_values,
+ use_cache=use_cache,
+ output_attentions=output_attentions,
+ output_hidden_states=output_hidden_states,
+ return_dict=return_dict,
+ is_decoder=is_decoder,
+ mode=mode,
+ )
+
+ sequence_output = outputs[0]
+ prediction_scores = self.cls(sequence_output)
+
+ if return_logits:
+ return prediction_scores[:, :-1, :].contiguous()
+
+ lm_loss = None
+ if labels is not None:
+ # we are doing next-token prediction; shift prediction scores and input ids by one
+ shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
+ labels = labels[:, 1:].contiguous()
+ loss_fct = CrossEntropyLoss(reduction=reduction, label_smoothing=0.1)
+ lm_loss = loss_fct(shifted_prediction_scores.view(-1, self.config.vocab_size), labels.view(-1))
+ if reduction=='none':
+ lm_loss = lm_loss.view(prediction_scores.size(0),-1).sum(1)
+
+ if not return_dict:
+ output = (prediction_scores,) + outputs[2:]
+ return ((lm_loss,) + output) if lm_loss is not None else output
+
+ return CausalLMOutputWithCrossAttentions(
+ loss=lm_loss,
+ logits=prediction_scores,
+ past_key_values=outputs.past_key_values,
+ hidden_states=outputs.hidden_states,
+ attentions=outputs.attentions,
+ cross_attentions=outputs.cross_attentions,
+ )
+
+ def prepare_inputs_for_generation(self, input_ids, past=None, attention_mask=None, **model_kwargs):
+ input_shape = input_ids.shape
+ # if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
+ if attention_mask is None:
+ attention_mask = input_ids.new_ones(input_shape)
+
+ # cut decoder_input_ids if past is used
+ if past is not None:
+ input_ids = input_ids[:, -1:]
+
+ return {
+ "input_ids": input_ids,
+ "attention_mask": attention_mask,
+ "past_key_values": past,
+ "encoder_hidden_states": model_kwargs.get("encoder_hidden_states", None),
+ "encoder_attention_mask": model_kwargs.get("encoder_attention_mask", None),
+ "is_decoder": True,
+ }
+
+ def _reorder_cache(self, past, beam_idx):
+ reordered_past = ()
+ for layer_past in past:
+ reordered_past += (tuple(past_state.index_select(0, beam_idx) for past_state in layer_past),)
+ return reordered_past
diff --git a/models/vit.py b/models/vit.py
new file mode 100644
index 0000000..135c0d5
--- /dev/null
+++ b/models/vit.py
@@ -0,0 +1,305 @@
+'''
+ * Copyright (c) 2022, salesforce.com, inc.
+ * All rights reserved.
+ * SPDX-License-Identifier: BSD-3-Clause
+ * For full license text, see LICENSE.txt file in the repo root or https://opensource.org/licenses/BSD-3-Clause
+ * By Junnan Li
+ * Based on timm code base
+ * https://github.com/rwightman/pytorch-image-models/tree/master/timm
+'''
+
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+from functools import partial
+
+from timm.models.vision_transformer import _cfg, PatchEmbed
+from timm.models.registry import register_model
+from timm.models.layers import trunc_normal_, DropPath
+from timm.models.helpers import named_apply, adapt_input_conv
+
+#from fairscale.nn.checkpoint.checkpoint_activations import checkpoint_wrapper
+
+class Mlp(nn.Module):
+ """ MLP as used in Vision Transformer, MLP-Mixer and related networks
+ """
+ def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
+ super().__init__()
+ out_features = out_features or in_features
+ hidden_features = hidden_features or in_features
+ self.fc1 = nn.Linear(in_features, hidden_features)
+ self.act = act_layer()
+ self.fc2 = nn.Linear(hidden_features, out_features)
+ self.drop = nn.Dropout(drop)
+
+ def forward(self, x):
+ x = self.fc1(x)
+ x = self.act(x)
+ x = self.drop(x)
+ x = self.fc2(x)
+ x = self.drop(x)
+ return x
+
+
+class Attention(nn.Module):
+ def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
+ super().__init__()
+ self.num_heads = num_heads
+ head_dim = dim // num_heads
+ # NOTE scale factor was wrong in my original version, can set manually to be compat with prev weights
+ self.scale = qk_scale or head_dim ** -0.5
+ self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
+ self.attn_drop = nn.Dropout(attn_drop)
+ self.proj = nn.Linear(dim, dim)
+ self.proj_drop = nn.Dropout(proj_drop)
+ self.attn_gradients = None
+ self.attention_map = None
+
+ def save_attn_gradients(self, attn_gradients):
+ self.attn_gradients = attn_gradients
+
+ def get_attn_gradients(self):
+ return self.attn_gradients
+
+ def save_attention_map(self, attention_map):
+ self.attention_map = attention_map
+
+ def get_attention_map(self):
+ return self.attention_map
+
+ def forward(self, x, register_hook=False):
+ B, N, C = x.shape
+ qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
+ q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)
+
+ attn = (q @ k.transpose(-2, -1)) * self.scale
+ attn = attn.softmax(dim=-1)
+ attn = self.attn_drop(attn)
+
+ if register_hook:
+ self.save_attention_map(attn)
+ attn.register_hook(self.save_attn_gradients)
+
+ x = (attn @ v).transpose(1, 2).reshape(B, N, C)
+ x = self.proj(x)
+ x = self.proj_drop(x)
+ return x
+
+
+class Block(nn.Module):
+
+ def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
+ drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, use_grad_checkpointing=False):
+ super().__init__()
+ self.norm1 = norm_layer(dim)
+ self.attn = Attention(
+ dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
+ # NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
+ self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
+ self.norm2 = norm_layer(dim)
+ mlp_hidden_dim = int(dim * mlp_ratio)
+ self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
+
+ #if use_grad_checkpointing:
+ # self.attn = checkpoint_wrapper(self.attn)
+ # self.mlp = checkpoint_wrapper(self.mlp)
+
+ def forward(self, x, register_hook=False):
+ x = x + self.drop_path(self.attn(self.norm1(x), register_hook=register_hook))
+ x = x + self.drop_path(self.mlp(self.norm2(x)))
+ return x
+
+
+class VisionTransformer(nn.Module):
+ """ Vision Transformer
+ A PyTorch impl of : `An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale` -
+ https://arxiv.org/abs/2010.11929
+ """
+ def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dim=768, depth=12,
+ num_heads=12, mlp_ratio=4., qkv_bias=True, qk_scale=None, representation_size=None,
+ drop_rate=0., attn_drop_rate=0., drop_path_rate=0., norm_layer=None,
+ use_grad_checkpointing=False, ckpt_layer=0):
+ """
+ Args:
+ img_size (int, tuple): input image size
+ patch_size (int, tuple): patch size
+ in_chans (int): number of input channels
+ num_classes (int): number of classes for classification head
+ embed_dim (int): embedding dimension
+ depth (int): depth of transformer
+ num_heads (int): number of attention heads
+ mlp_ratio (int): ratio of mlp hidden dim to embedding dim
+ qkv_bias (bool): enable bias for qkv if True
+ qk_scale (float): override default qk scale of head_dim ** -0.5 if set
+ representation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if set
+ drop_rate (float): dropout rate
+ attn_drop_rate (float): attention dropout rate
+ drop_path_rate (float): stochastic depth rate
+ norm_layer: (nn.Module): normalization layer
+ """
+ super().__init__()
+ self.num_features = self.embed_dim = embed_dim # num_features for consistency with other models
+ norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
+
+ self.patch_embed = PatchEmbed(
+ img_size=img_size, patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
+
+ num_patches = self.patch_embed.num_patches
+
+ self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
+ self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, embed_dim))
+ self.pos_drop = nn.Dropout(p=drop_rate)
+
+ dpr = [x.item() for x in torch.linspace(0, drop_path_rate, depth)] # stochastic depth decay rule
+ self.blocks = nn.ModuleList([
+ Block(
+ dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
+ drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer,
+ use_grad_checkpointing=(use_grad_checkpointing and i>=depth-ckpt_layer)
+ )
+ for i in range(depth)])
+ self.norm = norm_layer(embed_dim)
+
+ trunc_normal_(self.pos_embed, std=.02)
+ trunc_normal_(self.cls_token, std=.02)
+ self.apply(self._init_weights)
+
+ def _init_weights(self, m):
+ if isinstance(m, nn.Linear):
+ trunc_normal_(m.weight, std=.02)
+ if isinstance(m, nn.Linear) and m.bias is not None:
+ nn.init.constant_(m.bias, 0)
+ elif isinstance(m, nn.LayerNorm):
+ nn.init.constant_(m.bias, 0)
+ nn.init.constant_(m.weight, 1.0)
+
+ @torch.jit.ignore
+ def no_weight_decay(self):
+ return {'pos_embed', 'cls_token'}
+
+ def forward(self, x, register_blk=-1):
+ B = x.shape[0]
+ x = self.patch_embed(x)
+
+ cls_tokens = self.cls_token.expand(B, -1, -1) # stole cls_tokens impl from Phil Wang, thanks
+ x = torch.cat((cls_tokens, x), dim=1)
+
+ x = x + self.pos_embed[:,:x.size(1),:]
+ x = self.pos_drop(x)
+
+ for i,blk in enumerate(self.blocks):
+ x = blk(x, register_blk==i)
+ x = self.norm(x)
+
+ return x
+
+ @torch.jit.ignore()
+ def load_pretrained(self, checkpoint_path, prefix=''):
+ _load_weights(self, checkpoint_path, prefix)
+
+
+@torch.no_grad()
+def _load_weights(model: VisionTransformer, checkpoint_path: str, prefix: str = ''):
+ """ Load weights from .npz checkpoints for official Google Brain Flax implementation
+ """
+ import numpy as np
+
+ def _n2p(w, t=True):
+ if w.ndim == 4 and w.shape[0] == w.shape[1] == w.shape[2] == 1:
+ w = w.flatten()
+ if t:
+ if w.ndim == 4:
+ w = w.transpose([3, 2, 0, 1])
+ elif w.ndim == 3:
+ w = w.transpose([2, 0, 1])
+ elif w.ndim == 2:
+ w = w.transpose([1, 0])
+ return torch.from_numpy(w)
+
+ w = np.load(checkpoint_path)
+ if not prefix and 'opt/target/embedding/kernel' in w:
+ prefix = 'opt/target/'
+
+ if hasattr(model.patch_embed, 'backbone'):
+ # hybrid
+ backbone = model.patch_embed.backbone
+ stem_only = not hasattr(backbone, 'stem')
+ stem = backbone if stem_only else backbone.stem
+ stem.conv.weight.copy_(adapt_input_conv(stem.conv.weight.shape[1], _n2p(w[f'{prefix}conv_root/kernel'])))
+ stem.norm.weight.copy_(_n2p(w[f'{prefix}gn_root/scale']))
+ stem.norm.bias.copy_(_n2p(w[f'{prefix}gn_root/bias']))
+ if not stem_only:
+ for i, stage in enumerate(backbone.stages):
+ for j, block in enumerate(stage.blocks):
+ bp = f'{prefix}block{i + 1}/unit{j + 1}/'
+ for r in range(3):
+ getattr(block, f'conv{r + 1}').weight.copy_(_n2p(w[f'{bp}conv{r + 1}/kernel']))
+ getattr(block, f'norm{r + 1}').weight.copy_(_n2p(w[f'{bp}gn{r + 1}/scale']))
+ getattr(block, f'norm{r + 1}').bias.copy_(_n2p(w[f'{bp}gn{r + 1}/bias']))
+ if block.downsample is not None:
+ block.downsample.conv.weight.copy_(_n2p(w[f'{bp}conv_proj/kernel']))
+ block.downsample.norm.weight.copy_(_n2p(w[f'{bp}gn_proj/scale']))
+ block.downsample.norm.bias.copy_(_n2p(w[f'{bp}gn_proj/bias']))
+ embed_conv_w = _n2p(w[f'{prefix}embedding/kernel'])
+ else:
+ embed_conv_w = adapt_input_conv(
+ model.patch_embed.proj.weight.shape[1], _n2p(w[f'{prefix}embedding/kernel']))
+ model.patch_embed.proj.weight.copy_(embed_conv_w)
+ model.patch_embed.proj.bias.copy_(_n2p(w[f'{prefix}embedding/bias']))
+ model.cls_token.copy_(_n2p(w[f'{prefix}cls'], t=False))
+ pos_embed_w = _n2p(w[f'{prefix}Transformer/posembed_input/pos_embedding'], t=False)
+ if pos_embed_w.shape != model.pos_embed.shape:
+ pos_embed_w = resize_pos_embed( # resize pos embedding when different size from pretrained weights
+ pos_embed_w, model.pos_embed, getattr(model, 'num_tokens', 1), model.patch_embed.grid_size)
+ model.pos_embed.copy_(pos_embed_w)
+ model.norm.weight.copy_(_n2p(w[f'{prefix}Transformer/encoder_norm/scale']))
+ model.norm.bias.copy_(_n2p(w[f'{prefix}Transformer/encoder_norm/bias']))
+# if isinstance(model.head, nn.Linear) and model.head.bias.shape[0] == w[f'{prefix}head/bias'].shape[-1]:
+# model.head.weight.copy_(_n2p(w[f'{prefix}head/kernel']))
+# model.head.bias.copy_(_n2p(w[f'{prefix}head/bias']))
+# if isinstance(getattr(model.pre_logits, 'fc', None), nn.Linear) and f'{prefix}pre_logits/bias' in w:
+# model.pre_logits.fc.weight.copy_(_n2p(w[f'{prefix}pre_logits/kernel']))
+# model.pre_logits.fc.bias.copy_(_n2p(w[f'{prefix}pre_logits/bias']))
+ for i, block in enumerate(model.blocks.children()):
+ block_prefix = f'{prefix}Transformer/encoderblock_{i}/'
+ mha_prefix = block_prefix + 'MultiHeadDotProductAttention_1/'
+ block.norm1.weight.copy_(_n2p(w[f'{block_prefix}LayerNorm_0/scale']))
+ block.norm1.bias.copy_(_n2p(w[f'{block_prefix}LayerNorm_0/bias']))
+ block.attn.qkv.weight.copy_(torch.cat([
+ _n2p(w[f'{mha_prefix}{n}/kernel'], t=False).flatten(1).T for n in ('query', 'key', 'value')]))
+ block.attn.qkv.bias.copy_(torch.cat([
+ _n2p(w[f'{mha_prefix}{n}/bias'], t=False).reshape(-1) for n in ('query', 'key', 'value')]))
+ block.attn.proj.weight.copy_(_n2p(w[f'{mha_prefix}out/kernel']).flatten(1))
+ block.attn.proj.bias.copy_(_n2p(w[f'{mha_prefix}out/bias']))
+ for r in range(2):
+ getattr(block.mlp, f'fc{r + 1}').weight.copy_(_n2p(w[f'{block_prefix}MlpBlock_3/Dense_{r}/kernel']))
+ getattr(block.mlp, f'fc{r + 1}').bias.copy_(_n2p(w[f'{block_prefix}MlpBlock_3/Dense_{r}/bias']))
+ block.norm2.weight.copy_(_n2p(w[f'{block_prefix}LayerNorm_2/scale']))
+ block.norm2.bias.copy_(_n2p(w[f'{block_prefix}LayerNorm_2/bias']))
+
+
+def interpolate_pos_embed(pos_embed_checkpoint, visual_encoder):
+ # interpolate position embedding
+ embedding_size = pos_embed_checkpoint.shape[-1]
+ num_patches = visual_encoder.patch_embed.num_patches
+ num_extra_tokens = visual_encoder.pos_embed.shape[-2] - num_patches
+ # height (== width) for the checkpoint position embedding
+ orig_size = int((pos_embed_checkpoint.shape[-2] - num_extra_tokens) ** 0.5)
+ # height (== width) for the new position embedding
+ new_size = int(num_patches ** 0.5)
+
+ if orig_size!=new_size:
+ # class_token and dist_token are kept unchanged
+ extra_tokens = pos_embed_checkpoint[:, :num_extra_tokens]
+ # only the position tokens are interpolated
+ pos_tokens = pos_embed_checkpoint[:, num_extra_tokens:]
+ pos_tokens = pos_tokens.reshape(-1, orig_size, orig_size, embedding_size).permute(0, 3, 1, 2)
+ pos_tokens = torch.nn.functional.interpolate(
+ pos_tokens, size=(new_size, new_size), mode='bicubic', align_corners=False)
+ pos_tokens = pos_tokens.permute(0, 2, 3, 1).flatten(1, 2)
+ new_pos_embed = torch.cat((extra_tokens, pos_tokens), dim=1)
+ print('reshape position embedding from %d to %d'%(orig_size ** 2,new_size ** 2))
+
+ return new_pos_embed
+ else:
+ return pos_embed_checkpoint
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000..9c8c547
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,6 @@
+torch>=1.9.0
+torchvision>=0.10.0
+Pillow
+towhee
+timm
+transformers>=4.15.0
diff --git a/tabular1.png b/tabular1.png
new file mode 100644
index 0000000..8d1db62
Binary files /dev/null and b/tabular1.png differ
diff --git a/tabular2.png b/tabular2.png
new file mode 100644
index 0000000..26a46a6
Binary files /dev/null and b/tabular2.png differ
diff --git a/vec1.png b/vec1.png
new file mode 100644
index 0000000..b0022d1
Binary files /dev/null and b/vec1.png differ
diff --git a/vec2.png b/vec2.png
new file mode 100644
index 0000000..1e2adc0
Binary files /dev/null and b/vec2.png differ