
copied
Readme
Files and versions
4.7 KiB
Image Captioning with CaMEL
author: David Wang
Description
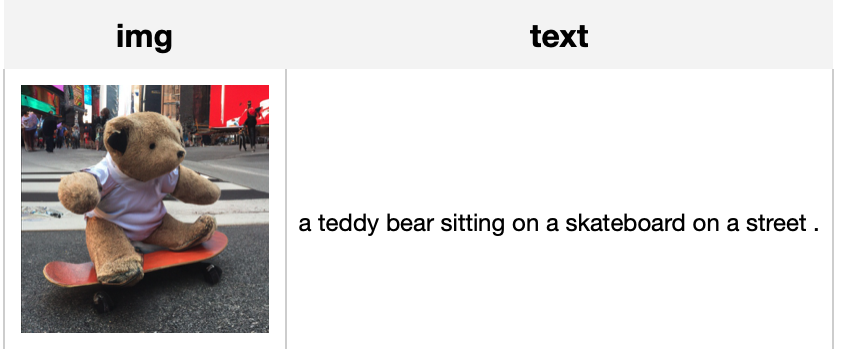
This operator generates the caption with CaMEL which describes the content of the given image. CaMEL is a novel Transformer-based architecture for image captioning which leverages the interaction of two interconnected language models that learn from each other during the training phase. The interplay between the two language models follows a mean teacher learning paradigm with knowledge distillation. This is an adaptation from aimagelab/camel.
Code Example
Load an image from path './image.jpg' to generate the caption.
Write the pipeline in simplified style:
import towhee
towhee.glob('./image.jpg') \
.image_decode() \
.image_captioning.camel(model_name='camel_mesh') \
.show()

Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
towhee.glob['path']('./image.jpg') \
.image_decode['path', 'img']() \
.image_captioning.camel['img', 'text'](model_name='camel_mesh') \
.select['img', 'text']() \
.show()
Factory Constructor
Create the operator via the following factory method
camel(model_name)
Parameters:
model_name: str
The model name of CaMEL. Supported model names:
- camel_mesh
Interface
An image captioning operator takes a towhee image as input and generate the correspoing caption.
Parameters:
data: towhee.types.Image (a sub-class of numpy.ndarray)
The image to generate caption.
Returns: str
The caption generated by model.
# More Resources
- [What is a Transformer Model? An Engineer's Guide](https://zilliz.com/glossary/transformer-models): A transformer model is a neural network architecture. It's proficient in converting a particular type of input into a distinct output. Its core strength lies in its ability to handle inputs and outputs of different sequence length. It does this through encoding the input into a matrix with predefined dimensions and then combining that with another attention matrix to decode. This transformation unfolds through a sequence of collaborative layers, which deconstruct words into their corresponding numerical representations.
At its heart, a transformer model is a bridge between disparate linguistic structures, employing sophisticated neural network configurations to decode and manipulate human language input. An example of a transformer model is GPT-3, which ingests human language and generates text output.
- Multimodal RAG locally with CLIP and Llama3 - Zilliz blog: A tutorial walks you through how to build a multimodal RAG with CLIP, Llama3, and Milvus.
- Transforming Text: The Rise of Sentence Transformers in NLP - Zilliz blog: Everything you need to know about the Transformers model, exploring its architecture, implementation, and limitations
- Supercharged Semantic Similarity Search in Production - Zilliz blog: Building a Blazing Fast, Highly Scalable Text-to-Image Search with CLIP embeddings and Milvus, the most advanced open-source vector database.
- The guide to clip-vit-base-patch32 | OpenAI: clip-vit-base-patch32: a CLIP multimodal model variant by OpenAI for image and text embedding.
- The guide to gte-base-en-v1.5 | Alibaba: gte-base-en-v1.5: specialized for English text; Built upon the transformer++ encoder backbone (BERT + RoPE + GLU)
- An LLM Powered Text to Image Prompt Generation with Milvus - Zilliz blog: An interesting LLM project powered by the Milvus vector database for generating more efficient text-to-image prompts.
- From Text to Image: Fundamentals of CLIP - Zilliz blog: Search algorithms rely on semantic similarity to retrieve the most relevant results. With the CLIP model, the semantics of texts and images can be connected in a high-dimensional vector space. Read this simple introduction to see how CLIP can help you build a powerful text-to-image service.
- Zilliz partnership with PyTorch - View image search solution tutorial: Zilliz partnership with PyTorch
4.7 KiB
Image Captioning with CaMEL
author: David Wang
Description
This operator generates the caption with CaMEL which describes the content of the given image. CaMEL is a novel Transformer-based architecture for image captioning which leverages the interaction of two interconnected language models that learn from each other during the training phase. The interplay between the two language models follows a mean teacher learning paradigm with knowledge distillation. This is an adaptation from aimagelab/camel.
Code Example
Load an image from path './image.jpg' to generate the caption.
Write the pipeline in simplified style:
import towhee
towhee.glob('./image.jpg') \
.image_decode() \
.image_captioning.camel(model_name='camel_mesh') \
.show()
Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
towhee.glob['path']('./image.jpg') \
.image_decode['path', 'img']() \
.image_captioning.camel['img', 'text'](model_name='camel_mesh') \
.select['img', 'text']() \
.show()
Factory Constructor
Create the operator via the following factory method
camel(model_name)
Parameters:
model_name: str
The model name of CaMEL. Supported model names:
- camel_mesh
Interface
An image captioning operator takes a towhee image as input and generate the correspoing caption.
Parameters:
data: towhee.types.Image (a sub-class of numpy.ndarray)
The image to generate caption.
Returns: str
The caption generated by model.
# More Resources
- [What is a Transformer Model? An Engineer's Guide](https://zilliz.com/glossary/transformer-models): A transformer model is a neural network architecture. It's proficient in converting a particular type of input into a distinct output. Its core strength lies in its ability to handle inputs and outputs of different sequence length. It does this through encoding the input into a matrix with predefined dimensions and then combining that with another attention matrix to decode. This transformation unfolds through a sequence of collaborative layers, which deconstruct words into their corresponding numerical representations.
At its heart, a transformer model is a bridge between disparate linguistic structures, employing sophisticated neural network configurations to decode and manipulate human language input. An example of a transformer model is GPT-3, which ingests human language and generates text output.
- Multimodal RAG locally with CLIP and Llama3 - Zilliz blog: A tutorial walks you through how to build a multimodal RAG with CLIP, Llama3, and Milvus.
- Transforming Text: The Rise of Sentence Transformers in NLP - Zilliz blog: Everything you need to know about the Transformers model, exploring its architecture, implementation, and limitations
- Supercharged Semantic Similarity Search in Production - Zilliz blog: Building a Blazing Fast, Highly Scalable Text-to-Image Search with CLIP embeddings and Milvus, the most advanced open-source vector database.
- The guide to clip-vit-base-patch32 | OpenAI: clip-vit-base-patch32: a CLIP multimodal model variant by OpenAI for image and text embedding.
- The guide to gte-base-en-v1.5 | Alibaba: gte-base-en-v1.5: specialized for English text; Built upon the transformer++ encoder backbone (BERT + RoPE + GLU)
- An LLM Powered Text to Image Prompt Generation with Milvus - Zilliz blog: An interesting LLM project powered by the Milvus vector database for generating more efficient text-to-image prompts.
- From Text to Image: Fundamentals of CLIP - Zilliz blog: Search algorithms rely on semantic similarity to retrieve the most relevant results. With the CLIP model, the semantics of texts and images can be connected in a high-dimensional vector space. Read this simple introduction to see how CLIP can help you build a powerful text-to-image service.
- Zilliz partnership with PyTorch - View image search solution tutorial: Zilliz partnership with PyTorch