diff --git a/README.md b/README.md
index c88b310..34307c5 100644
--- a/README.md
+++ b/README.md
@@ -1,2 +1,84 @@
-# dolg
+# Image Embdding with DOLG
+
+*author: David Wang*
+
+
+
+## Desription
+
+This operator extracts features for image with [DOLG](https://arxiv.org/abs/2108.02927) which has special design for image retrieval task. It integrates local and global information inside images into compact image representations. This operator is an adaptation from [dongkyuk/DOLG-pytorch](https://github.com/dongkyuk/DOLG-pytorch).
+
+## Code Example
+
+Load an image from path './towhee.jpg' to generate an image embedding.
+
+ *Write the pipeline in simplified style*:
+
+```python
+import towhee
+
+towhee.glob('./towhee.jpg') \
+ .image_decode.cv2() \
+ .image_embedding.dolg(img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048) \
+ .show()
+
+```
+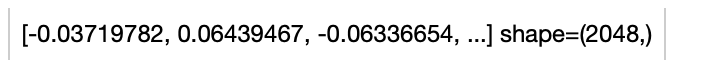 +
+*Write a same pipeline with explicit inputs/outputs name specifications:*
+
+```python
+import towhee
+
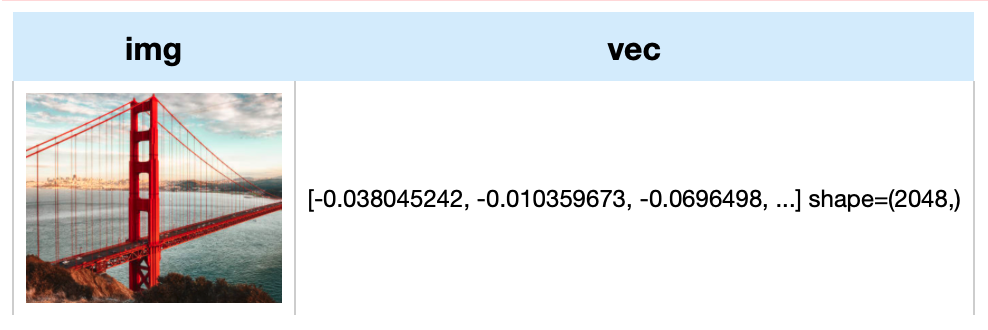
+towhee.glob['path']('./towhee.jpg') \
+ .image_decode.cv2['path', 'img']() \
+ .image_embedding.dolg['img', 'vec'](img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048) \
+ .select('img', 'vec') \
+ .show()
+```
+
+
+*Write a same pipeline with explicit inputs/outputs name specifications:*
+
+```python
+import towhee
+
+towhee.glob['path']('./towhee.jpg') \
+ .image_decode.cv2['path', 'img']() \
+ .image_embedding.dolg['img', 'vec'](img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048) \
+ .select('img', 'vec') \
+ .show()
+```
+ +
+## Factory Constructor
+
+Create the operator via the following factory method
+
+***image_embedding.dolg(img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048)***
+
+**Parameters:**
+
+ ***img_size***: *int*
+
+ Scaled input image size to extract embedding. The higher resolution would generate the more discriminateive feature but cost more time to calculate.
+
+ ***input_dim***: *int*
+
+ The input dimension of DOLG module (equals pretrained cnn output dimension).
+
+ ***hidden_dim***: *int*
+
+ The hidden dimension size, local feature branch output dimension.
+
+ ***output_dim***: *int*
+
+ The output dimsion size, same as embedding size.
+
+## Interface
+
+An image embedding operator takes a [towhee image](link/to/towhee/image/api/doc) as input.
+It uses the pre-trained model specified by model name to generate an image embedding in ndarray.
+
+
+**Parameters:**
+
+ ***img***: *towhee.types.Image (a sub-class of numpy.ndarray)*
+
+ The decoded image data in towhee.types.Image (numpy.ndarray).
+
+
+
+**Returns**: *numpy.ndarray*
+
+ The image embedding extracted by model.
+
+
diff --git a/__init__.py b/__init__.py
new file mode 100644
index 0000000..7519ec9
--- /dev/null
+++ b/__init__.py
@@ -0,0 +1,19 @@
+# Copyright 2021 Zilliz. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .dolg import Swintransformer
+
+def dolg(img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048):
+ return Dolg(img_size, input_dim, hidden_dim, output_dim)
+
diff --git a/dolg.py b/dolg.py
new file mode 100644
index 0000000..d4806b7
--- /dev/null
+++ b/dolg.py
@@ -0,0 +1,52 @@
+# Copyright 2021 Zilliz. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import logging
+import numpy
+import towhee
+import sys
+from pathlib import Path
+from torchvision import transforms
+from towhee.types.image_utils import to_pil
+
+from towhee.operator.base import NNOperator, OperatorFlag
+from towhee.types.arg import arg, to_image_color
+from towhee import register
+
+@register(output_schema=['vec'])
+class Dolg(NNOperator):
+ """
+ DOLG Embedding Operator
+ """
+ def __init__(self, img_size, input_dim, hidden_dim, output_dim):
+ super().__init__()
+ sys.path.append(str(Path(__file__).parent))
+ from dolg_impl import DolgNet
+ self.model = DolgNet(img_size, input_dim, hidden_dim, output_dim)
+ normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ self.tfms = transforms.Compose([transforms.Resize([img_size, img_size]),
+ transforms.Scale([img_size, img_size]),
+ transforms.ToTensor(),
+ normalize])
+
+ @arg(1, to_image_color('RGB'))
+ def __call__(self, img: numpy.ndarray):
+ img = self.tfms(to_pil(img)).unsqueeze(0)
+ self.model.eval()
+ features = self.model(img)
+ feature_vector = features.flatten().detach().numpy()
+ return feature_vector
+
diff --git a/dolg_impl.py b/dolg_impl.py
new file mode 100644
index 0000000..844e539
--- /dev/null
+++ b/dolg_impl.py
@@ -0,0 +1,129 @@
+import timm
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.optim as optim
+
+class GeM(nn.Module):
+ def __init__(self, p=3, eps=1e-6, requires_grad=False):
+ super(GeM, self).__init__()
+ self.p = nn.Parameter(torch.ones(1)*p, requires_grad=requires_grad)
+ self.eps = eps
+
+ def forward(self, x):
+ return self.gem(x, p=self.p, eps=self.eps)
+
+ def gem(self, x, p=3, eps=1e-6):
+ return F.avg_pool2d(x.clamp(min=eps).pow(p), (x.size(-2), x.size(-1))).pow(1./p)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(' + 'p=' + '{:.4f}'.format(self.p.data.tolist()[0]) + ', ' + 'eps=' + str(self.eps) + ')'
+
+class MultiAtrous(nn.Module):
+ def __init__(self, in_channel, out_channel, size, dilation_rates=[3, 6, 9]):
+ super().__init__()
+ self.dilated_convs = [
+ nn.Conv2d(in_channel, int(out_channel/4),
+ kernel_size=3, dilation=rate, padding=rate)
+ for rate in dilation_rates
+ ]
+ self.gap_branch = nn.Sequential(
+ nn.AdaptiveAvgPool2d(1),
+ nn.Conv2d(in_channel, int(out_channel/4), kernel_size=1),
+ nn.ReLU(),
+ nn.Upsample(size=(size, size), mode='bilinear')
+ )
+ self.dilated_convs.append(self.gap_branch)
+ self.dilated_convs = nn.ModuleList(self.dilated_convs)
+
+ def forward(self, x):
+ local_feat = []
+ for dilated_conv in self.dilated_convs:
+ local_feat.append(dilated_conv(x))
+ local_feat = torch.cat(local_feat, dim=1)
+ return local_feat
+
+
+class DolgLocalBranch(nn.Module):
+ def __init__(self, img_size, in_channel, out_channel, hidden_channel=2048):
+ super().__init__()
+ self.multi_atrous = MultiAtrous(in_channel, hidden_channel, size=int(img_size/8))
+ self.conv1x1_1 = nn.Conv2d(hidden_channel, out_channel, kernel_size=1)
+ self.conv1x1_2 = nn.Conv2d(
+ out_channel, out_channel, kernel_size=1, bias=False)
+ self.conv1x1_3 = nn.Conv2d(out_channel, out_channel, kernel_size=1)
+
+ self.relu = nn.ReLU()
+ self.bn = nn.BatchNorm2d(out_channel)
+ self.softplus = nn.Softplus()
+
+ def forward(self, x):
+ local_feat = self.multi_atrous(x)
+
+ local_feat = self.conv1x1_1(local_feat)
+ local_feat = self.relu(local_feat)
+ local_feat = self.conv1x1_2(local_feat)
+ local_feat = self.bn(local_feat)
+
+ attention_map = self.relu(local_feat)
+ attention_map = self.conv1x1_3(attention_map)
+ attention_map = self.softplus(attention_map)
+
+ local_feat = F.normalize(local_feat, p=2, dim=1)
+ local_feat = local_feat * attention_map
+
+ return local_feat
+
+class OrthogonalFusion(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, local_feat, global_feat):
+ global_feat_norm = torch.norm(global_feat, p=2, dim=1)
+ projection = torch.bmm(global_feat.unsqueeze(1), torch.flatten(
+ local_feat, start_dim=2))
+ projection = torch.bmm(global_feat.unsqueeze(
+ 2), projection).view(local_feat.size())
+ projection = projection / \
+ (global_feat_norm * global_feat_norm).view(-1, 1, 1, 1)
+ orthogonal_comp = local_feat - projection
+ global_feat = global_feat.unsqueeze(-1).unsqueeze(-1)
+ return torch.cat([global_feat.expand(orthogonal_comp.size()), orthogonal_comp], dim=1)
+
+class DolgNet(nn.Module):
+ def __init__(self, img_size, input_dim, hidden_dim, output_dim):
+ super().__init__()
+ self.cnn = timm.create_model(
+ 'tv_resnet101',
+ pretrained=True,
+ features_only=True,
+ in_chans=input_dim,
+ out_indices=(2, 3)
+ )
+ self.orthogonal_fusion = OrthogonalFusion()
+ self.local_branch = DolgLocalBranch(img_size, 512, hidden_dim)
+ self.gap = nn.AdaptiveAvgPool2d(1)
+ self.gem_pool = GeM()
+ self.fc_1 = nn.Linear(1024, hidden_dim)
+ self.fc_2 = nn.Linear(int(2*hidden_dim), output_dim)
+#
+# self.criterion = ArcFace(
+# in_features=output_dim,
+# out_features=num_of_classes,
+# scale_factor=30,
+# margin=0.15,
+# criterion=nn.CrossEntropyLoss()
+# )
+#
+ def forward(self, x):
+ output = self.cnn(x)
+
+ local_feat = self.local_branch(output[0]) # ,hidden_channel,16,16
+ global_feat = self.fc_1(self.gem_pool(output[1]).squeeze(3).squeeze(2)) # ,1024
+
+ feat = self.orthogonal_fusion(local_feat, global_feat)
+ feat = self.gap(feat).squeeze()
+ feat = self.fc_2(feat)
+
+ return feat
+
diff --git a/result1.png b/result1.png
new file mode 100644
index 0000000..438b368
Binary files /dev/null and b/result1.png differ
diff --git a/result2.png b/result2.png
new file mode 100644
index 0000000..9126178
Binary files /dev/null and b/result2.png differ
+
+## Factory Constructor
+
+Create the operator via the following factory method
+
+***image_embedding.dolg(img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048)***
+
+**Parameters:**
+
+ ***img_size***: *int*
+
+ Scaled input image size to extract embedding. The higher resolution would generate the more discriminateive feature but cost more time to calculate.
+
+ ***input_dim***: *int*
+
+ The input dimension of DOLG module (equals pretrained cnn output dimension).
+
+ ***hidden_dim***: *int*
+
+ The hidden dimension size, local feature branch output dimension.
+
+ ***output_dim***: *int*
+
+ The output dimsion size, same as embedding size.
+
+## Interface
+
+An image embedding operator takes a [towhee image](link/to/towhee/image/api/doc) as input.
+It uses the pre-trained model specified by model name to generate an image embedding in ndarray.
+
+
+**Parameters:**
+
+ ***img***: *towhee.types.Image (a sub-class of numpy.ndarray)*
+
+ The decoded image data in towhee.types.Image (numpy.ndarray).
+
+
+
+**Returns**: *numpy.ndarray*
+
+ The image embedding extracted by model.
+
+
diff --git a/__init__.py b/__init__.py
new file mode 100644
index 0000000..7519ec9
--- /dev/null
+++ b/__init__.py
@@ -0,0 +1,19 @@
+# Copyright 2021 Zilliz. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .dolg import Swintransformer
+
+def dolg(img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048):
+ return Dolg(img_size, input_dim, hidden_dim, output_dim)
+
diff --git a/dolg.py b/dolg.py
new file mode 100644
index 0000000..d4806b7
--- /dev/null
+++ b/dolg.py
@@ -0,0 +1,52 @@
+# Copyright 2021 Zilliz. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+
+import logging
+import numpy
+import towhee
+import sys
+from pathlib import Path
+from torchvision import transforms
+from towhee.types.image_utils import to_pil
+
+from towhee.operator.base import NNOperator, OperatorFlag
+from towhee.types.arg import arg, to_image_color
+from towhee import register
+
+@register(output_schema=['vec'])
+class Dolg(NNOperator):
+ """
+ DOLG Embedding Operator
+ """
+ def __init__(self, img_size, input_dim, hidden_dim, output_dim):
+ super().__init__()
+ sys.path.append(str(Path(__file__).parent))
+ from dolg_impl import DolgNet
+ self.model = DolgNet(img_size, input_dim, hidden_dim, output_dim)
+ normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
+ std=[0.229, 0.224, 0.225])
+ self.tfms = transforms.Compose([transforms.Resize([img_size, img_size]),
+ transforms.Scale([img_size, img_size]),
+ transforms.ToTensor(),
+ normalize])
+
+ @arg(1, to_image_color('RGB'))
+ def __call__(self, img: numpy.ndarray):
+ img = self.tfms(to_pil(img)).unsqueeze(0)
+ self.model.eval()
+ features = self.model(img)
+ feature_vector = features.flatten().detach().numpy()
+ return feature_vector
+
diff --git a/dolg_impl.py b/dolg_impl.py
new file mode 100644
index 0000000..844e539
--- /dev/null
+++ b/dolg_impl.py
@@ -0,0 +1,129 @@
+import timm
+import torch
+import torch.nn as nn
+import torch.nn.functional as F
+import torch.optim as optim
+
+class GeM(nn.Module):
+ def __init__(self, p=3, eps=1e-6, requires_grad=False):
+ super(GeM, self).__init__()
+ self.p = nn.Parameter(torch.ones(1)*p, requires_grad=requires_grad)
+ self.eps = eps
+
+ def forward(self, x):
+ return self.gem(x, p=self.p, eps=self.eps)
+
+ def gem(self, x, p=3, eps=1e-6):
+ return F.avg_pool2d(x.clamp(min=eps).pow(p), (x.size(-2), x.size(-1))).pow(1./p)
+
+ def __repr__(self):
+ return self.__class__.__name__ + '(' + 'p=' + '{:.4f}'.format(self.p.data.tolist()[0]) + ', ' + 'eps=' + str(self.eps) + ')'
+
+class MultiAtrous(nn.Module):
+ def __init__(self, in_channel, out_channel, size, dilation_rates=[3, 6, 9]):
+ super().__init__()
+ self.dilated_convs = [
+ nn.Conv2d(in_channel, int(out_channel/4),
+ kernel_size=3, dilation=rate, padding=rate)
+ for rate in dilation_rates
+ ]
+ self.gap_branch = nn.Sequential(
+ nn.AdaptiveAvgPool2d(1),
+ nn.Conv2d(in_channel, int(out_channel/4), kernel_size=1),
+ nn.ReLU(),
+ nn.Upsample(size=(size, size), mode='bilinear')
+ )
+ self.dilated_convs.append(self.gap_branch)
+ self.dilated_convs = nn.ModuleList(self.dilated_convs)
+
+ def forward(self, x):
+ local_feat = []
+ for dilated_conv in self.dilated_convs:
+ local_feat.append(dilated_conv(x))
+ local_feat = torch.cat(local_feat, dim=1)
+ return local_feat
+
+
+class DolgLocalBranch(nn.Module):
+ def __init__(self, img_size, in_channel, out_channel, hidden_channel=2048):
+ super().__init__()
+ self.multi_atrous = MultiAtrous(in_channel, hidden_channel, size=int(img_size/8))
+ self.conv1x1_1 = nn.Conv2d(hidden_channel, out_channel, kernel_size=1)
+ self.conv1x1_2 = nn.Conv2d(
+ out_channel, out_channel, kernel_size=1, bias=False)
+ self.conv1x1_3 = nn.Conv2d(out_channel, out_channel, kernel_size=1)
+
+ self.relu = nn.ReLU()
+ self.bn = nn.BatchNorm2d(out_channel)
+ self.softplus = nn.Softplus()
+
+ def forward(self, x):
+ local_feat = self.multi_atrous(x)
+
+ local_feat = self.conv1x1_1(local_feat)
+ local_feat = self.relu(local_feat)
+ local_feat = self.conv1x1_2(local_feat)
+ local_feat = self.bn(local_feat)
+
+ attention_map = self.relu(local_feat)
+ attention_map = self.conv1x1_3(attention_map)
+ attention_map = self.softplus(attention_map)
+
+ local_feat = F.normalize(local_feat, p=2, dim=1)
+ local_feat = local_feat * attention_map
+
+ return local_feat
+
+class OrthogonalFusion(nn.Module):
+ def __init__(self):
+ super().__init__()
+
+ def forward(self, local_feat, global_feat):
+ global_feat_norm = torch.norm(global_feat, p=2, dim=1)
+ projection = torch.bmm(global_feat.unsqueeze(1), torch.flatten(
+ local_feat, start_dim=2))
+ projection = torch.bmm(global_feat.unsqueeze(
+ 2), projection).view(local_feat.size())
+ projection = projection / \
+ (global_feat_norm * global_feat_norm).view(-1, 1, 1, 1)
+ orthogonal_comp = local_feat - projection
+ global_feat = global_feat.unsqueeze(-1).unsqueeze(-1)
+ return torch.cat([global_feat.expand(orthogonal_comp.size()), orthogonal_comp], dim=1)
+
+class DolgNet(nn.Module):
+ def __init__(self, img_size, input_dim, hidden_dim, output_dim):
+ super().__init__()
+ self.cnn = timm.create_model(
+ 'tv_resnet101',
+ pretrained=True,
+ features_only=True,
+ in_chans=input_dim,
+ out_indices=(2, 3)
+ )
+ self.orthogonal_fusion = OrthogonalFusion()
+ self.local_branch = DolgLocalBranch(img_size, 512, hidden_dim)
+ self.gap = nn.AdaptiveAvgPool2d(1)
+ self.gem_pool = GeM()
+ self.fc_1 = nn.Linear(1024, hidden_dim)
+ self.fc_2 = nn.Linear(int(2*hidden_dim), output_dim)
+#
+# self.criterion = ArcFace(
+# in_features=output_dim,
+# out_features=num_of_classes,
+# scale_factor=30,
+# margin=0.15,
+# criterion=nn.CrossEntropyLoss()
+# )
+#
+ def forward(self, x):
+ output = self.cnn(x)
+
+ local_feat = self.local_branch(output[0]) # ,hidden_channel,16,16
+ global_feat = self.fc_1(self.gem_pool(output[1]).squeeze(3).squeeze(2)) # ,1024
+
+ feat = self.orthogonal_fusion(local_feat, global_feat)
+ feat = self.gap(feat).squeeze()
+ feat = self.fc_2(feat)
+
+ return feat
+
diff --git a/result1.png b/result1.png
new file mode 100644
index 0000000..438b368
Binary files /dev/null and b/result1.png differ
diff --git a/result2.png b/result2.png
new file mode 100644
index 0000000..9126178
Binary files /dev/null and b/result2.png differ