# Image Embdding with DOLG
*author: David Wang*
## Description
This operator extracts features for image with [DOLG](https://arxiv.org/abs/2108.02927) which has special design for image retrieval task. It integrates local and global information inside images into compact image representations. This operator is an adaptation from [dongkyuk/DOLG-pytorch](https://github.com/dongkyuk/DOLG-pytorch).
## Code Example
Load an image from path './towhee.jpg' to generate an image embedding.
*Write the pipeline in simplified style*:
```python
import towhee
towhee.glob('./towhee.jpg') \
.image_decode.cv2() \
.image_embedding.dolg(img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048) \
.show()
```
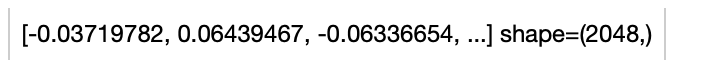 *Write a same pipeline with explicit inputs/outputs name specifications:*
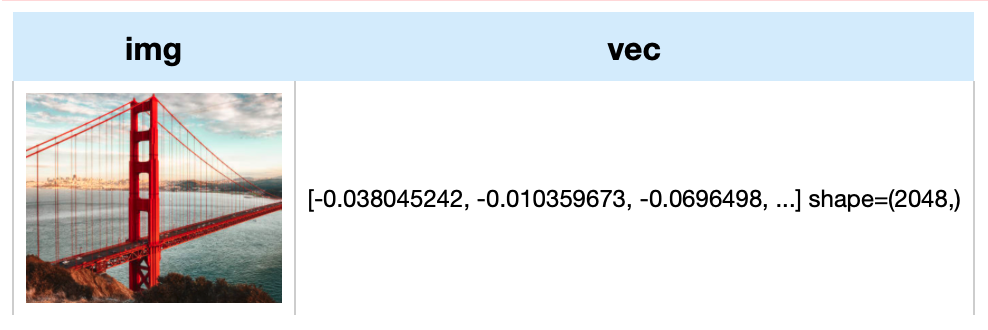
```python
import towhee
towhee.glob['path']('./towhee.jpg') \
.image_decode.cv2['path', 'img']() \
.image_embedding.dolg['img', 'vec'](img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048) \
.select['img', 'vec']() \
.show()
```
*Write a same pipeline with explicit inputs/outputs name specifications:*
```python
import towhee
towhee.glob['path']('./towhee.jpg') \
.image_decode.cv2['path', 'img']() \
.image_embedding.dolg['img', 'vec'](img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048) \
.select['img', 'vec']() \
.show()
```
## Factory Constructor
Create the operator via the following factory method
***image_embedding.dolg(img_size=512, input_dim=3, hidden_dim=1024, output_dim=2048)***
**Parameters:**
***img_size:*** *int*
Scaled input image size to extract embedding. The higher resolution would generate the more discriminateive feature but cost more time to calculate.
***input_dim:*** *int*
The input dimension of DOLG module (equals pretrained cnn output dimension).
***hidden_dim:*** *int*
The hidden dimension size, local feature branch output dimension.
***output_dim:*** *int*
The output dimsion size, same as embedding size.
## Interface
An image embedding operator takes a [towhee image](link/to/towhee/image/api/doc) as input.
It uses the pre-trained model specified by model name to generate an image embedding in ndarray.
**Parameters:**
***img:*** *towhee.types.Image (a sub-class of numpy.ndarray)*
The decoded image data in towhee.types.Image (numpy.ndarray).
**Returns:** *numpy.ndarray*
The image embedding extracted by model.
# More Resources
- [Scalar Quantization and Product Quantization - Zilliz blog](https://zilliz.com/learn/scalar-quantization-and-product-quantization): A hands-on dive into scalar quantization (integer quantization) and product quantization with Python.
- [Multimodal RAG with Milvus and GPT-4o](https://zilliz.com/event/multimodal-rag-with-milvus-and-gpt-4o/success): Join us for a webinar for a demo of multimodal RAG with Milvus and GPT-4o
- [How to Get the Right Vector Embeddings - Zilliz blog](https://zilliz.com/blog/how-to-get-the-right-vector-embeddings): A comprehensive introduction to vector embeddings and how to generate them with popular open-source models.
- [Using Vector Search to Better Understand Computer Vision Data - Zilliz blog](https://zilliz.com/blog/use-vector-search-to-better-understand-computer-vision-data): How Vector Search improves your understanding of Computer Vision Data
- [Multimodal RAG with Milvus and GPT-4o](https://zilliz.com/event/multimodal-rag-with-milvus-and-gpt-4o): Join us for a webinar for a demo of multimodal RAG with Milvus and GPT-4o
- [What is Detection Transformers (DETR)? - Zilliz blog](https://zilliz.com/learn/detection-transformers-detr-end-to-end-object-detection-with-transformers): DETR (DEtection TRansformer) is a deep learning model for end-to-end object detection using transformers.
- [Image Embeddings for Enhanced Image Search - Zilliz blog](https://zilliz.com/learn/image-embeddings-for-enhanced-image-search): Image Embeddings are the core of modern computer vision algorithms. Understand their implementation and use cases and explore different image embedding models.