
copied
Readme
Files and versions
Updated 4 years ago
image-embedding
Image Embedding with MPViT
author: Chen Zhang
Description
This operator extracts features for images with Multi-Path Vision Transformer (MPViT) which can generate embeddings for images. MPViT embeds features of the same size~(i.e., sequence length) with patches of different scales simultaneously by using overlapping convolutional patch embedding. Tokens of different scales are then independently fed into the Transformer encoders via multiple paths and the resulting features are aggregated, enabling both fine and coarse feature representations at the same feature level.
Code Example
Load an image from path 'towhee.jpeg' and use the pre-trained 'mpvit_base' model to generate an image embedding.
Write a same pipeline with explicit inputs/outputs name specifications:
from towhee.dc2 import pipe, ops, DataCollection
p = (
pipe.input('path')
.map('path', 'img', ops.image_decode())
.map('img', 'vec', ops.image_embedding.mpvit(model_name='mpvit_base'))
.output('img', 'vec')
)
DataCollection(p('towhee.jpeg')).show()

Factory Constructor
Create the operator via the following factory method:
image_embedding.mpvit(model_name='mpvit_base', **kwargs)
Parameters:
model_name: str
Pretrained model name include mpvit_tiny, mpvit_xsmall, mpvit_small or mpvit_base, all of which are pretrained on ImageNet-1K dataset, for more information, please refer the original MPViT github page.
weights_path: str
Your local weights path, default is None, which means using the pretrained model weights.
device: str
Model device, cpu or cuda.
num_classes: int
The number of classes. The default value is 1000. It is related to model and dataset. If you want to fine-tune this operator, you can change this value to adapt your datasets.
skip_preprocess: bool
The flag to control whether to skip image pre-process. The default value is False. If set to True, it will skip image preprocessing steps (transforms). In this case, input image data must be prepared in advance in order to properly fit the model.
Interface
An image embedding operator takes a towhee image as input. It uses the pre-trained model specified by model name to generate an image embedding in ndarray.
Parameters:
data: towhee._types.Image
The decoded image data in towhee Image (a subset of numpy.ndarray).
Returns: numpy.ndarray
An image embedding generated by model, in shape of (feature_dim,).
For mpvit_tiny model, feature_dim = 216.
For mpvit_xsmall model, feature_dim = 256.
For mpvit_small model, feature_dim = 288.
For mpvit_base model, feature_dim = 480.
|
| 4 Commits | ||
|---|---|---|---|
 .gitattributes
.gitattributes
|
1.1 KiB
|
4 years ago | |
|
README.md
|
2.8 KiB
|
4 years ago | |
|
__init__.py
|
698 B
|
4 years ago | |
|
mpvit.py
|
2.8 KiB
|
4 years ago | |
|
requirements.txt
|
54 B
|
4 years ago | |
|
result.png
|
81 KiB

|
4 years ago | |
|
result1.png
|
16 KiB
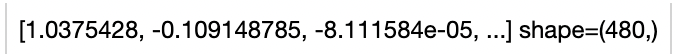
|
4 years ago | |
|
result2.png
|
136 KiB

|
4 years ago | |
|
towhee.jpeg
|
49 KiB

|
4 years ago | |
{kind=link}
{kind=link}
{kind=link}
{kind=link}