diff --git a/README.md b/README.md
index f72af4a..af94275 100644
--- a/README.md
+++ b/README.md
@@ -21,38 +21,27 @@ Load an image from path './teddy.jpg' to generate an image embedding.
Read the text 'A teddybear on a skateboard in Times Square.' to generate an text embedding.
- *Write the pipeline in simplified style*:
+*Write a pipeline with explicit inputs/outputs name specifications:*
```python
-import towhee
+from towhee.dc2 import pipe, ops, DataCollection
-towhee.glob('./teddy.jpg') \
- .image_decode() \
- .image_text_embedding.blip(model_name='blip_base', modality='image') \
- .show()
+img_pipe = (
+ pipe.input('url')
+ .map('url', 'img', ops.image_decode.cv2_rgb())
+ .map('img', 'vec', ops.image_text_embedding.blip(model_name='blip_itm_base', modality='image'))
+ .output('img', 'vec')
+)
-towhee.dc(["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.blip(model_name='blip_base', modality='text') \
- .show()
-```
-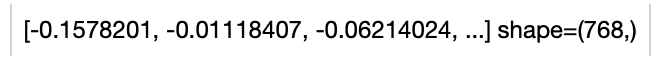 -
- +text_pipe = (
+ pipe.input('text')
+ .map('text', 'vec', ops.image_text_embedding.blip(model_name='blip_itm_base', modality='text'))
+ .output('text', 'vec')
+)
-*Write a same pipeline with explicit inputs/outputs name specifications:*
+DataCollection(image_pipe('./teddy.jpg')).show()
+DataCollection(text_pipe('A teddybear on a skateboard in Times Square.')).show()
-```python
-import towhee
-
-towhee.glob['path']('./teddy.jpg') \
- .image_decode['path', 'img']() \
- .image_text_embedding.blip['img', 'vec'](model_name='blip_base', modality='image') \
- .select['img', 'vec']() \
- .show()
-
-towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.blip['text','vec'](model_name='blip_base', modality='text') \
- .select['text', 'vec']() \
- .show()
```
+text_pipe = (
+ pipe.input('text')
+ .map('text', 'vec', ops.image_text_embedding.blip(model_name='blip_itm_base', modality='text'))
+ .output('text', 'vec')
+)
-*Write a same pipeline with explicit inputs/outputs name specifications:*
+DataCollection(image_pipe('./teddy.jpg')).show()
+DataCollection(text_pipe('A teddybear on a skateboard in Times Square.')).show()
-```python
-import towhee
-
-towhee.glob['path']('./teddy.jpg') \
- .image_decode['path', 'img']() \
- .image_text_embedding.blip['img', 'vec'](model_name='blip_base', modality='image') \
- .select['img', 'vec']() \
- .show()
-
-towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.blip['text','vec'](model_name='blip_base', modality='text') \
- .select['text', 'vec']() \
- .show()
```

 @@ -73,7 +62,7 @@ Create the operator via the following factory method
***model_name:*** *str*
The model name of BLIP. Supported model names:
-- blip_base
+- blip_itm_base
***modality:*** *str*
diff --git a/blip.py b/blip.py
index ea6e062..b17c577 100644
--- a/blip.py
+++ b/blip.py
@@ -16,66 +16,202 @@ import sys
from pathlib import Path
import torch
-from torchvision import transforms
-from torchvision.transforms.functional import InterpolationMode
+from torch import nn
+from transformers import AutoProcessor, BlipForImageTextRetrieval
+from transformers import logging as t_logging
from towhee import register
from towhee.operator.base import NNOperator, OperatorFlag
from towhee.types.arg import arg, to_image_color
-from towhee.types.image_utils import from_pil, to_pil
+
+log = logging.getLogger('run_op')
+warnings.filterwarnings('ignore')
+os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
+t_logging.set_verbosity_error()
+
+#@accelerate
+class BLIPModelVision(nn.Module):
+ def __init__(self, model):
+ super().__init__()
+ self.model = model
+
+ def forward(self, image):
+ image_embeds = self.model.visual_encoder(image)
+ image_embeds = self.model.vision_proj(image_embeds[:,0,:])
+ return image_embeds
+
+#@accelerate
+class BLIPModelText(nn.Module):
+ def __init__(self, model):
+ super().__init__()
+ self.model = model
+
+ def forward(self, input_ids, attention_mask):
+ text_features = self.model.text_encoder(input_ids, attention_mask = attention_mask,
+ return_dict = False)[0]
+ text_features = self.model.text_proj(text_features[:,0,:])
+ return text_features
@register(output_schema=['vec'])
class Blip(NNOperator):
"""
BLIP multi-modal embedding operator
"""
- def __init__(self, model_name: str, modality: str):
+ def __init__(self, model_name: str, modality: str, device:str = 'cpu', checkpoint_path: str = None):
super().__init__()
- sys.path.append(str(Path(__file__).parent))
- from models.blip import blip_feature_extractor
- image_size = 224
- model_url = self._configs()[model_name]['weights']
- self.model = blip_feature_extractor(pretrained=model_url, image_size=image_size, vit='base')
+ self.modality = modality
+ self.model_name = model_name
+ self.device = device
+ cfg = self._configs()[model_name]
+
+ try:
+ blip_model = BlipForImageTextRetrieval.from_pretrained(cfg)
+ except Exception as e:
+ log.error(f'Fail to load model by name: {self.model_name}')
+ raise e
+ if checkpoint_path:
+ try:
+ state_dict = torch.load(checkpoint_path, map_location=self.device)
+ self.model.load_state_dict(state_dict)
+ except Exception as e:
+ log.error(f'Fail to load state dict from {checkpoint_path}: {e}')
+ self.processor = AutoProcessor.from_pretrained('Salesforce/blip-itm-base-coco')
+
+ if self.modality == 'image':
+ self.model = BLIPModelVision(blip_model)
+ elif self.modality == 'text':
+ self.model = BLIPModelText(blip_model)
+ else:
+ raise ValueError('modality[{}] not implemented.'.format(self.modality))
self._modality = modality
- self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model.to(self.device)
self.model.eval()
- self.tfms = transforms.Compose([
- transforms.Resize((image_size,image_size),interpolation=InterpolationMode.BICUBIC),
- transforms.ToTensor(),
- transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
- ])
-
def __call__(self, data):
if self._modality == 'image':
vec = self._inference_from_image(data)
elif self._modality == 'text':
vec = self._inference_from_text(data)
else:
- raise ValueError("modality[{}] not implemented.".format(self._modality))
+ raise ValueError('modality[{}] not implemented.'.format(self._modality))
return vec.detach().cpu().numpy().flatten()
def _inference_from_text(self, text):
- text_feature = self.model(None, text, mode='text', device=self.device)[0,0]
+ inputs = self.processor(text=text, padding=True, return_tensors='pt')
+ inputs = inputs.to(self.device)
+ text_feature = self.model(input_ids = inputs.input_ids, attention_mask = inputs.attention_mask)[0]
return text_feature
@arg(1, to_image_color('RGB'))
def _inference_from_image(self, img):
- img = self._preprocess(img)
- caption = ''
- image_feature = self.model(img, caption, mode='image', device=self.device)[0,0]
+ inputs = self.processor(images=img, return_tensors='pt')
+ inputs = inputs.to(self.device)
+ image_feature = self.model(inputs)
return image_feature
- def _preprocess(self, img):
- img = to_pil(img)
- processed_img = self.tfms(img).unsqueeze(0).to(self.device)
- return processed_img
-
def _configs(self):
config = {}
- config['blip_base'] = {}
- config['blip_base']['weights'] = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base.pth'
+ config['blip_itm_base'] = {}
+ config['blip_itm_base']['weights'] = 'Salesforce/blip-itm-base-coco'
+ config['blip_itm_base']['image_size'] = 224
return config
+ @property
+ def _model(self):
+ return self.model
+
+ def train(self, **kwargs):
+ raise NotImplementedError
+
+ @property
+ def supported_formats(self):
+ onnxes = self.supported_model_names(format='onnx')
+ if self.model_name in onnxes:
+ return ['onnx']
+ else:
+ return ['pytorch']
+
+ @staticmethod
+ def supported_model_names(format: str = None):
+ if format == 'pytorch' or format == 'torchscript' or format == 'onnx':
+ model_list = [
+ 'blip_itm_base',
+ ]
+ else:
+ log.error(f'Invalid format "{format}". Currently supported formats: "pytorch", "torchscript".')
+ return model_list
+
+ def save_model(self, model_type: str = 'pytorch', output_file: str = 'default'):
+ import os
+ from PIL import Image
+ from torch.onnx import export as onnx_export
+
+ if output_file == 'default':
+ output_file = str(Path(__file__).parent)
+ output_file = os.path.join(output_file, 'saved', model_type)
+ os.makedirs(output_file, exist_ok=True)
+ name = self.model_name.replace('/', '-')
+ output_file = os.path.join(output_file, name)
+ if model_type in ['pytorch', 'torchscript']:
+ output_file = output_file + '.pt'
+ elif model_type == 'onnx':
+ output_file = output_file + '.onnx'
+ else:
+ raise AttributeError('Unsupported model_type.')
+ if self.modality == 'image':
+ sz = self.processor.feature_extractor.crop_size
+ if isinstance(sz, int):
+ h = sz
+ w = sz
+ elif isinstance(sz, dict):
+ h = sz['height']
+ w = sz['width']
+ dummy_input = Image.new('RGB', (w, h), color = 'red')
+ inputs = self.processor(images=dummy_input, return_tensors='pt') # a dictionary
+ elif self.modality == 'text':
+ dummy_input = 'dummy'
+ inputs = self.processor(text=dummy_input, padding=True, return_tensors='pt')
+ else:
+ raise ValueError('modality[{}] not implemented.'.format(self.modality))
+
+ if model_type == 'pytorch':
+ torch.save(self._model, output_file)
+ elif model_type == 'torchscript':
+ inputs = list(inputs.values())
+ try:
+ try:
+ jit_model = torch.jit.script(self._model)
+ except Exception:
+ jit_model = torch.jit.trace(self._model, inputs, strict=False)
+ torch.jit.save(jit_model, output_file)
+ except Exception as e:
+ log.error(f'Fail to save as torchscript: {e}.')
+ raise RuntimeError(f'Fail to save as torchscript: {e}.')
+ elif model_type == 'onnx':
+ if self.modality == 'image':
+ input_names= ['pixel_values']
+ output_names=['image_embeds']
+ dynamic_axes={'pixel_values': {0: 'batch'}, 'image_embeds': {0: 'batch'}}
+ elif self.modality == 'text':
+ input_names= ['input_ids', 'attention_mask']
+ output_names=['text_embeds']
+ dynamic_axes={'input_ids': {0: 'batch', 1: 'sequence'}, 'attention_mask': {0: 'batch', 1: 'sequence'}, 'text_embeds': {0: 'batch'}}
+ else:
+ raise ValueError('modality[{}] not implemented.'.format(self.modality))
+
+ onnx_export(self.model,
+ (dict(inputs),),
+ f=Path(output_file),
+ input_names= input_names,
+ output_names=output_names,
+ dynamic_axes=dynamic_axes,
+ do_constant_folding=True,
+ opset_version=14,
+ )
+ else:
+ pass
+ raise NotImplementedError
+
+
diff --git a/requirements.txt b/requirements.txt
index 9c8c547..956f3a0 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -3,4 +3,4 @@ torchvision>=0.10.0
Pillow
towhee
timm
-transformers>=4.15.0
+transformers>=4.26.0
@@ -73,7 +62,7 @@ Create the operator via the following factory method
***model_name:*** *str*
The model name of BLIP. Supported model names:
-- blip_base
+- blip_itm_base
***modality:*** *str*
diff --git a/blip.py b/blip.py
index ea6e062..b17c577 100644
--- a/blip.py
+++ b/blip.py
@@ -16,66 +16,202 @@ import sys
from pathlib import Path
import torch
-from torchvision import transforms
-from torchvision.transforms.functional import InterpolationMode
+from torch import nn
+from transformers import AutoProcessor, BlipForImageTextRetrieval
+from transformers import logging as t_logging
from towhee import register
from towhee.operator.base import NNOperator, OperatorFlag
from towhee.types.arg import arg, to_image_color
-from towhee.types.image_utils import from_pil, to_pil
+
+log = logging.getLogger('run_op')
+warnings.filterwarnings('ignore')
+os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
+t_logging.set_verbosity_error()
+
+#@accelerate
+class BLIPModelVision(nn.Module):
+ def __init__(self, model):
+ super().__init__()
+ self.model = model
+
+ def forward(self, image):
+ image_embeds = self.model.visual_encoder(image)
+ image_embeds = self.model.vision_proj(image_embeds[:,0,:])
+ return image_embeds
+
+#@accelerate
+class BLIPModelText(nn.Module):
+ def __init__(self, model):
+ super().__init__()
+ self.model = model
+
+ def forward(self, input_ids, attention_mask):
+ text_features = self.model.text_encoder(input_ids, attention_mask = attention_mask,
+ return_dict = False)[0]
+ text_features = self.model.text_proj(text_features[:,0,:])
+ return text_features
@register(output_schema=['vec'])
class Blip(NNOperator):
"""
BLIP multi-modal embedding operator
"""
- def __init__(self, model_name: str, modality: str):
+ def __init__(self, model_name: str, modality: str, device:str = 'cpu', checkpoint_path: str = None):
super().__init__()
- sys.path.append(str(Path(__file__).parent))
- from models.blip import blip_feature_extractor
- image_size = 224
- model_url = self._configs()[model_name]['weights']
- self.model = blip_feature_extractor(pretrained=model_url, image_size=image_size, vit='base')
+ self.modality = modality
+ self.model_name = model_name
+ self.device = device
+ cfg = self._configs()[model_name]
+
+ try:
+ blip_model = BlipForImageTextRetrieval.from_pretrained(cfg)
+ except Exception as e:
+ log.error(f'Fail to load model by name: {self.model_name}')
+ raise e
+ if checkpoint_path:
+ try:
+ state_dict = torch.load(checkpoint_path, map_location=self.device)
+ self.model.load_state_dict(state_dict)
+ except Exception as e:
+ log.error(f'Fail to load state dict from {checkpoint_path}: {e}')
+ self.processor = AutoProcessor.from_pretrained('Salesforce/blip-itm-base-coco')
+
+ if self.modality == 'image':
+ self.model = BLIPModelVision(blip_model)
+ elif self.modality == 'text':
+ self.model = BLIPModelText(blip_model)
+ else:
+ raise ValueError('modality[{}] not implemented.'.format(self.modality))
self._modality = modality
- self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model.to(self.device)
self.model.eval()
- self.tfms = transforms.Compose([
- transforms.Resize((image_size,image_size),interpolation=InterpolationMode.BICUBIC),
- transforms.ToTensor(),
- transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
- ])
-
def __call__(self, data):
if self._modality == 'image':
vec = self._inference_from_image(data)
elif self._modality == 'text':
vec = self._inference_from_text(data)
else:
- raise ValueError("modality[{}] not implemented.".format(self._modality))
+ raise ValueError('modality[{}] not implemented.'.format(self._modality))
return vec.detach().cpu().numpy().flatten()
def _inference_from_text(self, text):
- text_feature = self.model(None, text, mode='text', device=self.device)[0,0]
+ inputs = self.processor(text=text, padding=True, return_tensors='pt')
+ inputs = inputs.to(self.device)
+ text_feature = self.model(input_ids = inputs.input_ids, attention_mask = inputs.attention_mask)[0]
return text_feature
@arg(1, to_image_color('RGB'))
def _inference_from_image(self, img):
- img = self._preprocess(img)
- caption = ''
- image_feature = self.model(img, caption, mode='image', device=self.device)[0,0]
+ inputs = self.processor(images=img, return_tensors='pt')
+ inputs = inputs.to(self.device)
+ image_feature = self.model(inputs)
return image_feature
- def _preprocess(self, img):
- img = to_pil(img)
- processed_img = self.tfms(img).unsqueeze(0).to(self.device)
- return processed_img
-
def _configs(self):
config = {}
- config['blip_base'] = {}
- config['blip_base']['weights'] = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base.pth'
+ config['blip_itm_base'] = {}
+ config['blip_itm_base']['weights'] = 'Salesforce/blip-itm-base-coco'
+ config['blip_itm_base']['image_size'] = 224
return config
+ @property
+ def _model(self):
+ return self.model
+
+ def train(self, **kwargs):
+ raise NotImplementedError
+
+ @property
+ def supported_formats(self):
+ onnxes = self.supported_model_names(format='onnx')
+ if self.model_name in onnxes:
+ return ['onnx']
+ else:
+ return ['pytorch']
+
+ @staticmethod
+ def supported_model_names(format: str = None):
+ if format == 'pytorch' or format == 'torchscript' or format == 'onnx':
+ model_list = [
+ 'blip_itm_base',
+ ]
+ else:
+ log.error(f'Invalid format "{format}". Currently supported formats: "pytorch", "torchscript".')
+ return model_list
+
+ def save_model(self, model_type: str = 'pytorch', output_file: str = 'default'):
+ import os
+ from PIL import Image
+ from torch.onnx import export as onnx_export
+
+ if output_file == 'default':
+ output_file = str(Path(__file__).parent)
+ output_file = os.path.join(output_file, 'saved', model_type)
+ os.makedirs(output_file, exist_ok=True)
+ name = self.model_name.replace('/', '-')
+ output_file = os.path.join(output_file, name)
+ if model_type in ['pytorch', 'torchscript']:
+ output_file = output_file + '.pt'
+ elif model_type == 'onnx':
+ output_file = output_file + '.onnx'
+ else:
+ raise AttributeError('Unsupported model_type.')
+ if self.modality == 'image':
+ sz = self.processor.feature_extractor.crop_size
+ if isinstance(sz, int):
+ h = sz
+ w = sz
+ elif isinstance(sz, dict):
+ h = sz['height']
+ w = sz['width']
+ dummy_input = Image.new('RGB', (w, h), color = 'red')
+ inputs = self.processor(images=dummy_input, return_tensors='pt') # a dictionary
+ elif self.modality == 'text':
+ dummy_input = 'dummy'
+ inputs = self.processor(text=dummy_input, padding=True, return_tensors='pt')
+ else:
+ raise ValueError('modality[{}] not implemented.'.format(self.modality))
+
+ if model_type == 'pytorch':
+ torch.save(self._model, output_file)
+ elif model_type == 'torchscript':
+ inputs = list(inputs.values())
+ try:
+ try:
+ jit_model = torch.jit.script(self._model)
+ except Exception:
+ jit_model = torch.jit.trace(self._model, inputs, strict=False)
+ torch.jit.save(jit_model, output_file)
+ except Exception as e:
+ log.error(f'Fail to save as torchscript: {e}.')
+ raise RuntimeError(f'Fail to save as torchscript: {e}.')
+ elif model_type == 'onnx':
+ if self.modality == 'image':
+ input_names= ['pixel_values']
+ output_names=['image_embeds']
+ dynamic_axes={'pixel_values': {0: 'batch'}, 'image_embeds': {0: 'batch'}}
+ elif self.modality == 'text':
+ input_names= ['input_ids', 'attention_mask']
+ output_names=['text_embeds']
+ dynamic_axes={'input_ids': {0: 'batch', 1: 'sequence'}, 'attention_mask': {0: 'batch', 1: 'sequence'}, 'text_embeds': {0: 'batch'}}
+ else:
+ raise ValueError('modality[{}] not implemented.'.format(self.modality))
+
+ onnx_export(self.model,
+ (dict(inputs),),
+ f=Path(output_file),
+ input_names= input_names,
+ output_names=output_names,
+ dynamic_axes=dynamic_axes,
+ do_constant_folding=True,
+ opset_version=14,
+ )
+ else:
+ pass
+ raise NotImplementedError
+
+
diff --git a/requirements.txt b/requirements.txt
index 9c8c547..956f3a0 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -3,4 +3,4 @@ torchvision>=0.10.0
Pillow
towhee
timm
-transformers>=4.15.0
+transformers>=4.26.0