diff --git a/README.md b/README.md
index 95ed7e1..37238f6 100644
--- a/README.md
+++ b/README.md
@@ -1,2 +1,109 @@
-# clip
+# Image-Text Retrieval Embdding with CLIP
+
+*author: David Wang*
+
+
+
+
+
+
+## Description
+
+This operator extracts features for image or text with [CLIP](https://arxiv.org/abs/2108.02927) which can generate embeddings for text and image by jointly training an image encoder and text encoder to maximize the cosine similarity.
+
+
+
+
+
+## Code Example
+
+Load an image from path './teddy.jpg' to generate an image embedding.
+
+Read the text 'A teddybear on a skateboard in Times Square.' to generate an text embedding.
+
+ *Write the pipeline in simplified style*:
+
+```python
+import towhee
+
+towhee.glob('./teddy.jpg') \
+ .image_decode() \
+ .image_text_embedding.clip(model_name='clip_vit_b32', modality='image') \
+ .show()
+
+towhee.dc(["A teddybear on a skateboard in Times Square."]) \
+ .image_text_embedding.clip(model_name='clip_vit_b32', modality='text') \
+ .show()
+```
+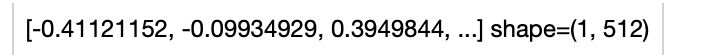 +
+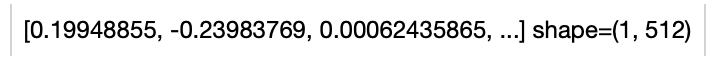 +
+*Write a same pipeline with explicit inputs/outputs name specifications:*
+
+```python
+import towhee
+
+towhee.glob['path']('./teddy.jpg') \
+ .image_decode['path', 'img']() \
+ .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_b32', modality='image') \
+ .select['img', 'vec']() \
+ .show()
+
+towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
+ .image_text_embedding.clip['text','vec'](model_name='clip_vit_b32', modality='text') \
+ .select['text', 'vec']() \
+ .show()
+```
+
+
+*Write a same pipeline with explicit inputs/outputs name specifications:*
+
+```python
+import towhee
+
+towhee.glob['path']('./teddy.jpg') \
+ .image_decode['path', 'img']() \
+ .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_b32', modality='image') \
+ .select['img', 'vec']() \
+ .show()
+
+towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
+ .image_text_embedding.clip['text','vec'](model_name='clip_vit_b32', modality='text') \
+ .select['text', 'vec']() \
+ .show()
+```
+ +
+ +
+
+
+
+
+
+
+
+
+## Factory Constructor
+
+Create the operator via the following factory method
+
+***clip(model_name, modality)***
+
+**Parameters:**
+
+ ***model_name:*** *str*
+
+ The model name of CLIP. Supported model names:
+- clip_resnet_r50
+- clip_resnet_r101
+- clip_vit_b32
+- clip_vit_b16
+
+
+ ***modality:*** *str*
+
+ Which modality(*image* or *text*) is used to generate the embedding.
+
+
+
+
+
+## Interface
+
+An image-text embedding operator takes a [towhee image](link/to/towhee/image/api/doc) or string as input and generate an embedding in ndarray.
+
+
+**Parameters:**
+
+ ***data:*** *towhee.types.Image (a sub-class of numpy.ndarray)* or *str*
+
+ The data (image or text based on specified modality) to generate embedding.
+
+
+
+**Returns:** *numpy.ndarray*
+
+ The data embedding extracted by model.
+
+
+
diff --git a/__init__.py b/__init__.py
new file mode 100644
index 0000000..8a0ea78
--- /dev/null
+++ b/__init__.py
@@ -0,0 +1,19 @@
+# Copyright 2021 Zilliz. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from .clip import Clip
+
+
+def clip(model_name: str, modality: str):
+ return Clip(model_name, modality)
diff --git a/clip.py b/clip.py
new file mode 100644
index 0000000..1db657c
--- /dev/null
+++ b/clip.py
@@ -0,0 +1,64 @@
+# Copyright 2021 Zilliz. All rights reserved.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+import sys
+from pathlib import Path
+import torch
+from torchvision import transforms
+
+from towhee.types.image_utils import to_pil
+from towhee.operator.base import NNOperator, OperatorFlag
+from towhee.types.arg import arg, to_image_color
+from towhee import register
+from towhee.models import clip
+
+
+@register(output_schema=['vec'])
+class Clip(NNOperator):
+ """
+ CLIP multi-modal embedding operator
+ """
+ def __init__(self, model_name: str, modality: str):
+ self.modality = modality
+ self.device = "cuda" if torch.cuda.is_available() else "cpu"
+ self.model = clip.create_model(model_name=model_name, pretrained=True, jit=True)
+ self.tokenize = clip.tokenize
+ self.tfms = transforms.Compose([
+ transforms.Resize(224, interpolation=transforms.InterpolationMode.BICUBIC),
+ transforms.CenterCrop(224),
+ transforms.ToTensor(),
+ transforms.Normalize(
+ (0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
+ ])
+
+ def __call__(self, data):
+ if self.modality == 'image':
+ vec = self._inference_from_image(data)
+ elif self.modality == 'text':
+ vec = self._inference_from_text(data)
+ else:
+ raise ValueError("modality[{}] not implemented.".format(self._modality))
+ return vec.detach().cpu().numpy().flatten()
+
+ def _inference_from_text(self, text):
+ text = self.tokenize(text).to(self.device)
+ text_features = self.model.encode_text(text)
+ return text_features
+
+ @arg(1, to_image_color('RGB'))
+ def _inference_from_image(self, img):
+ img = to_pil(img)
+ image = self.tfms(img).unsqueeze(0).to(self.device)
+ image_features = self.model.encode_image(image)
+ return image_features
diff --git a/tabular1.png b/tabular1.png
new file mode 100644
index 0000000..fb3e917
Binary files /dev/null and b/tabular1.png differ
diff --git a/tabular2.png b/tabular2.png
new file mode 100644
index 0000000..965a93a
Binary files /dev/null and b/tabular2.png differ
diff --git a/vec1.png b/vec1.png
new file mode 100644
index 0000000..5f60a86
Binary files /dev/null and b/vec1.png differ
diff --git a/vec2.png b/vec2.png
new file mode 100644
index 0000000..74d8257
Binary files /dev/null and b/vec2.png differ