diff --git a/README.md b/README.md
index 94e4010..9bd1496 100644
--- a/README.md
+++ b/README.md
@@ -28,11 +28,11 @@ import towhee
towhee.glob('./teddy.jpg') \
.image_decode() \
- .image_text_embedding.clip(model_name='clip_vit_b32', modality='image') \
+ .image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image') \
.show()
towhee.dc(["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.clip(model_name='clip_vit_b32', modality='text') \
+ .image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='text') \
.show()
```
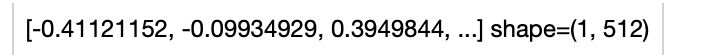 @@ -45,12 +45,12 @@ import towhee
towhee.glob['path']('./teddy.jpg') \
.image_decode['path', 'img']() \
- .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_b32', modality='image') \
+ .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_base_patch16', modality='image') \
.select['img', 'vec']() \
.show()
towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.clip['text','vec'](model_name='clip_vit_b32', modality='text') \
+ .image_text_embedding.clip['text','vec'](model_name='clip_vit_base_patch16', modality='text') \
.select['text', 'vec']() \
.show()
```
@@ -112,7 +112,7 @@ Save model to local with specified format.
```python
from towhee import ops
-op = ops.image_text_embedding.clip(model_name='clip_vit_base_16', modality='image').get_op()
+op = ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image').get_op()
op.save_model('onnx', 'test.onnx')
```
@@ -45,12 +45,12 @@ import towhee
towhee.glob['path']('./teddy.jpg') \
.image_decode['path', 'img']() \
- .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_b32', modality='image') \
+ .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_base_patch16', modality='image') \
.select['img', 'vec']() \
.show()
towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.clip['text','vec'](model_name='clip_vit_b32', modality='text') \
+ .image_text_embedding.clip['text','vec'](model_name='clip_vit_base_patch16', modality='text') \
.select['text', 'vec']() \
.show()
```
@@ -112,7 +112,7 @@ Save model to local with specified format.
```python
from towhee import ops
-op = ops.image_text_embedding.clip(model_name='clip_vit_base_16', modality='image').get_op()
+op = ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image').get_op()
op.save_model('onnx', 'test.onnx')
```
@@ -145,7 +145,7 @@ Get a list of all supported model names or supported model names for specified m
from towhee import ops
-op = towhee.ops.image_text_embedding.clip(model_name='clip_vit_base_16', modality='image').get_op()
+op = towhee.ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image').get_op()
full_list = op.supported_model_names()
onnx_list = op.supported_model_names(format='onnx')
print(f'Onnx-support/Total Models: {len(onnx_list)}/{len(full_list)}')
@@ -164,7 +164,7 @@ If you want to train this operator, besides dependency in requirements.txt, you
```python
import towhee
-clip_op = towhee.ops.image_text_embedding.clip(model_name='clip_vit_base_16', modality='image').get_op()
+clip_op = towhee.ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image').get_op()
data_args = {
'dataset_name': 'ydshieh/coco_dataset_script',
diff --git a/clip.py b/clip.py
index ec9f1fc..e3de597 100644
--- a/clip.py
+++ b/clip.py
@@ -172,7 +172,13 @@ class Clip(NNOperator):
raise AttributeError('Unsupported model_type.')
if self.modality == 'image':
sz = self.processor.feature_extractor.crop_size
- dummy_input = Image.new('RGB', (sz, sz), color = 'red')
+ if isinstance(sz, int):
+ h = sz
+ w = sz
+ elif isinstance(sz, dict):
+ h = sz['height']
+ w = sz['width']
+ dummy_input = Image.new('RGB', (w, h), color = 'red')
inputs = self.processor(images=dummy_input, return_tensors='pt') # a dictionary
elif self.modality == 'text':
dummy_input = 'dummy'