diff --git a/README.md b/README.md
index 9bd1496..9317c94 100644
--- a/README.md
+++ b/README.md
@@ -21,38 +21,27 @@ Load an image from path './teddy.jpg' to generate an image embedding.
Read the text 'A teddybear on a skateboard in Times Square.' to generate an text embedding.
- *Write the pipeline in simplified style*:
+*Write a pipeline with explicit inputs/outputs name specifications:*
```python
-import towhee
-
-towhee.glob('./teddy.jpg') \
- .image_decode() \
- .image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image') \
- .show()
-
-towhee.dc(["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='text') \
- .show()
-```
-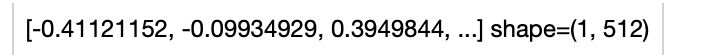 -
-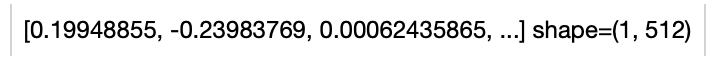 +from towhee.dc2 import pipe, ops, DataCollection
-*Write a same pipeline with explicit inputs/outputs name specifications:*
+img_pipe = (
+ pipe.input('url')
+ .map('url', 'img', ops.image_decode.cv2_rgb())
+ .map('img', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image'))
+ .output('img', 'vec')
+)
-```python
-import towhee
+text_pipe = (
+ pipe.input('text')
+ .map('text', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='text'))
+ .output('text', 'vec')
+)
-towhee.glob['path']('./teddy.jpg') \
- .image_decode['path', 'img']() \
- .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_base_patch16', modality='image') \
- .select['img', 'vec']() \
- .show()
+DataCollection(img_pipe('./teddy.jpg')).show()
+DataCollection(text_pipe('A teddybear on a skateboard in Times Square.')).show()
-towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.clip['text','vec'](model_name='clip_vit_base_patch16', modality='text') \
- .select['text', 'vec']() \
- .show()
```
+from towhee.dc2 import pipe, ops, DataCollection
-*Write a same pipeline with explicit inputs/outputs name specifications:*
+img_pipe = (
+ pipe.input('url')
+ .map('url', 'img', ops.image_decode.cv2_rgb())
+ .map('img', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image'))
+ .output('img', 'vec')
+)
-```python
-import towhee
+text_pipe = (
+ pipe.input('text')
+ .map('text', 'vec', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='text'))
+ .output('text', 'vec')
+)
-towhee.glob['path']('./teddy.jpg') \
- .image_decode['path', 'img']() \
- .image_text_embedding.clip['img', 'vec'](model_name='clip_vit_base_patch16', modality='image') \
- .select['img', 'vec']() \
- .show()
+DataCollection(img_pipe('./teddy.jpg')).show()
+DataCollection(text_pipe('A teddybear on a skateboard in Times Square.')).show()
-towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
- .image_text_embedding.clip['text','vec'](model_name='clip_vit_base_patch16', modality='text') \
- .select['text', 'vec']() \
- .show()
```

