diff --git a/README.md b/README.md
index 0811f1e..f5a32d3 100644
--- a/README.md
+++ b/README.md
@@ -35,8 +35,8 @@ towhee.dc(["A teddybear on a skateboard in Times Square."]) \
.image_text_embedding.lightningdot(modality='text') \
.show()
```
- -
- +
+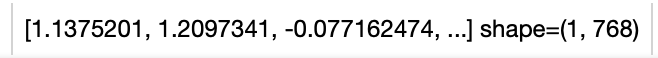 +
+ *Write a same pipeline with explicit inputs/outputs name specifications:*
@@ -66,10 +66,18 @@ towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
Create the operator via the following factory method
-***lightningdot(modality)***
+***lightningdot(model_name, modality)***
**Parameters:**
+
+ ***model_name:*** *str*
+
+ The model name of LightningDOT. Supported model names:
+- lightningdot_base
+- lightningdot_coco_ft
+- lightningdot_flickr_ft
+
***modality:*** *str*
Which modality(*image* or *text*) is used to generate the embedding.
diff --git a/lightningdot.py b/lightningdot.py
index fdc611e..c54b598 100644
--- a/lightningdot.py
+++ b/lightningdot.py
@@ -79,7 +79,7 @@ class LightningDOT(NNOperator):
state_dict[k[5:]] = state_dict.pop(k)
else:
state_dict.pop(k)
- bi_encoder.load_state_dict(state_dict, strict=True)
+ self.bi_encoder.load_state_dict(state_dict, strict=True)
img_model, txt_model = self.bi_encoder.img_model, self.bi_encoder.txt_model
img_model.eval()
@@ -138,7 +138,7 @@ class LightningDOT(NNOperator):
vec = self._inference_from_text(data)
else:
raise ValueError("modality[{}] not implemented.".format(self._modality))
- return vec.detach().cpu().numpy()
+ return vec.detach().cpu().numpy().flatten()
def _inference_from_text(self, data):
ids = self.tokenizer.encode(data)
*Write a same pipeline with explicit inputs/outputs name specifications:*
@@ -66,10 +66,18 @@ towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
Create the operator via the following factory method
-***lightningdot(modality)***
+***lightningdot(model_name, modality)***
**Parameters:**
+
+ ***model_name:*** *str*
+
+ The model name of LightningDOT. Supported model names:
+- lightningdot_base
+- lightningdot_coco_ft
+- lightningdot_flickr_ft
+
***modality:*** *str*
Which modality(*image* or *text*) is used to generate the embedding.
diff --git a/lightningdot.py b/lightningdot.py
index fdc611e..c54b598 100644
--- a/lightningdot.py
+++ b/lightningdot.py
@@ -79,7 +79,7 @@ class LightningDOT(NNOperator):
state_dict[k[5:]] = state_dict.pop(k)
else:
state_dict.pop(k)
- bi_encoder.load_state_dict(state_dict, strict=True)
+ self.bi_encoder.load_state_dict(state_dict, strict=True)
img_model, txt_model = self.bi_encoder.img_model, self.bi_encoder.txt_model
img_model.eval()
@@ -138,7 +138,7 @@ class LightningDOT(NNOperator):
vec = self._inference_from_text(data)
else:
raise ValueError("modality[{}] not implemented.".format(self._modality))
- return vec.detach().cpu().numpy()
+ return vec.detach().cpu().numpy().flatten()
def _inference_from_text(self, data):
ids = self.tokenizer.encode(data)