
copied
Readme
Files and versions
3.4 KiB
Object Detection with Yolo
author: shiyu22
Description
Object Detection is a computer vision technique that locates and identifies people, items, or other objects in an image. Object detection has applications in many areas of computer vision, including image retrieval, image annotation, vehicle counting, object tracking, etc.
This operator uses PyTorch.yolov5 to detect the object.
Code Example
Writing the pipeline in the simplified way
from towhee.dc2 import pipe, ops, DataCollection
p = (
pipe.input('url')
.map('url', 'img', ops.image_decode.cv2_rgb())
.flat_map('img', ('boxes', 'class', 'score'), ops.object_detection.yolo())
.flat_map(('img', 'boxes'), 'object', ops.towhee.image_crop())
.output('url', 'object', 'class', 'score')
)
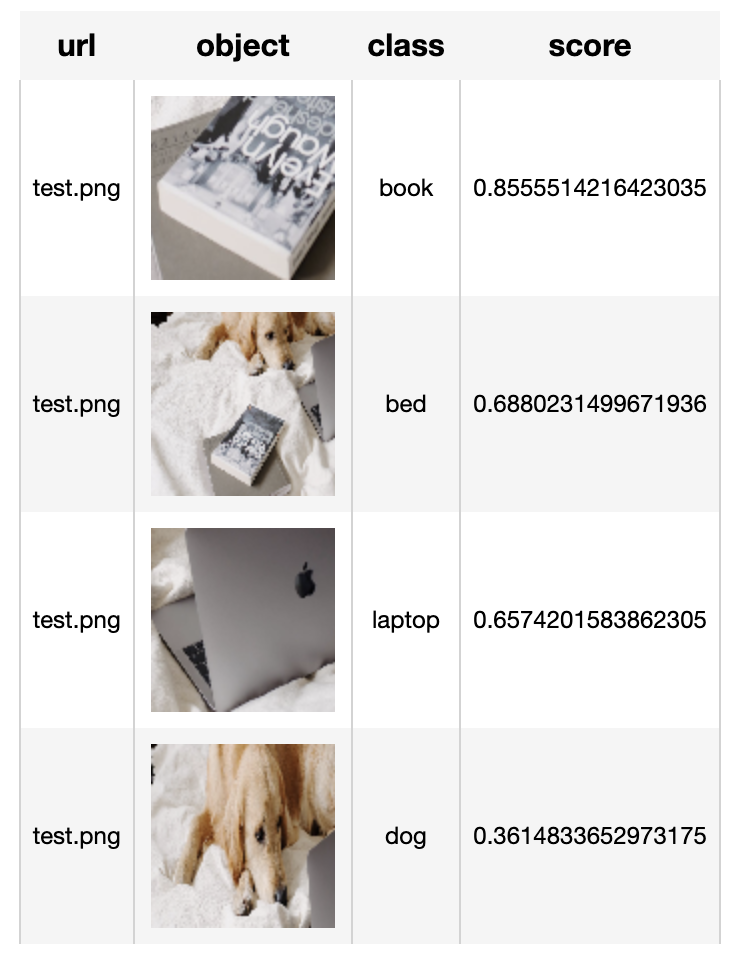
res = p('test.png')
DataCollection(res).show()
Factory Constructor
Create the operator via the following factory method
object_detection.yolo()
Interface
The operator takes an image as input. It first detects the objects appeared in the image, and gives the bounding box of each object.
Parameters:
img: numpy.ndarray
Image data in ndarray format.
Return: List[List[(int, int, int, int)], ...], List[str], List[float]]
The return value is a tuple of (boxes, classes, scores). The boxes is a list of bounding boxes. Each bounding box is represented by the top-left and the bottom right points, i.e. (x1, y1, x2, y2). The classes is a list of prediction labels. The scores is a list of the confidence scores.
More Resources
- CLIP Object Detection: Merging AI Vision with Language Understanding - Zilliz blog: CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.
- Computer Vision with FiftyOne | Milvus & Zilliz Cloud: nan
- What is a Convolutional Neural Network? An Engineer's Guide: Convolutional Neural Network is a type of deep neural network that processes images, speeches, and videos. Let's find out more about CNN.
- Understanding Computer Vision - Zilliz blog: Computer Vision is a field of Artificial Intelligence that enables machines to capture and interpret visual information from the world just like humans do.
- Using Vector Search to Better Understand Computer Vision Data - Zilliz blog: How Vector Search improves your understanding of Computer Vision Data
- What are Vision Transformers (ViT)? - Zilliz blog: Vision Transformers (ViTs) are neural network models that use transformers to perform computer vision tasks like object detection and image classification.
- What is Detection Transformers (DETR)? - Zilliz blog: DETR (DEtection TRansformer) is a deep learning model for end-to-end object detection using transformers.
3.4 KiB
Object Detection with Yolo
author: shiyu22
Description
Object Detection is a computer vision technique that locates and identifies people, items, or other objects in an image. Object detection has applications in many areas of computer vision, including image retrieval, image annotation, vehicle counting, object tracking, etc.
This operator uses PyTorch.yolov5 to detect the object.
Code Example
Writing the pipeline in the simplified way
from towhee.dc2 import pipe, ops, DataCollection
p = (
pipe.input('url')
.map('url', 'img', ops.image_decode.cv2_rgb())
.flat_map('img', ('boxes', 'class', 'score'), ops.object_detection.yolo())
.flat_map(('img', 'boxes'), 'object', ops.towhee.image_crop())
.output('url', 'object', 'class', 'score')
)
res = p('test.png')
DataCollection(res).show()
Factory Constructor
Create the operator via the following factory method
object_detection.yolo()
Interface
The operator takes an image as input. It first detects the objects appeared in the image, and gives the bounding box of each object.
Parameters:
img: numpy.ndarray
Image data in ndarray format.
Return: List[List[(int, int, int, int)], ...], List[str], List[float]]
The return value is a tuple of (boxes, classes, scores). The boxes is a list of bounding boxes. Each bounding box is represented by the top-left and the bottom right points, i.e. (x1, y1, x2, y2). The classes is a list of prediction labels. The scores is a list of the confidence scores.
More Resources
- CLIP Object Detection: Merging AI Vision with Language Understanding - Zilliz blog: CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.
- Computer Vision with FiftyOne | Milvus & Zilliz Cloud: nan
- What is a Convolutional Neural Network? An Engineer's Guide: Convolutional Neural Network is a type of deep neural network that processes images, speeches, and videos. Let's find out more about CNN.
- Understanding Computer Vision - Zilliz blog: Computer Vision is a field of Artificial Intelligence that enables machines to capture and interpret visual information from the world just like humans do.
- Using Vector Search to Better Understand Computer Vision Data - Zilliz blog: How Vector Search improves your understanding of Computer Vision Data
- What are Vision Transformers (ViT)? - Zilliz blog: Vision Transformers (ViTs) are neural network models that use transformers to perform computer vision tasks like object detection and image classification.
- What is Detection Transformers (DETR)? - Zilliz blog: DETR (DEtection TRansformer) is a deep learning model for end-to-end object detection using transformers.