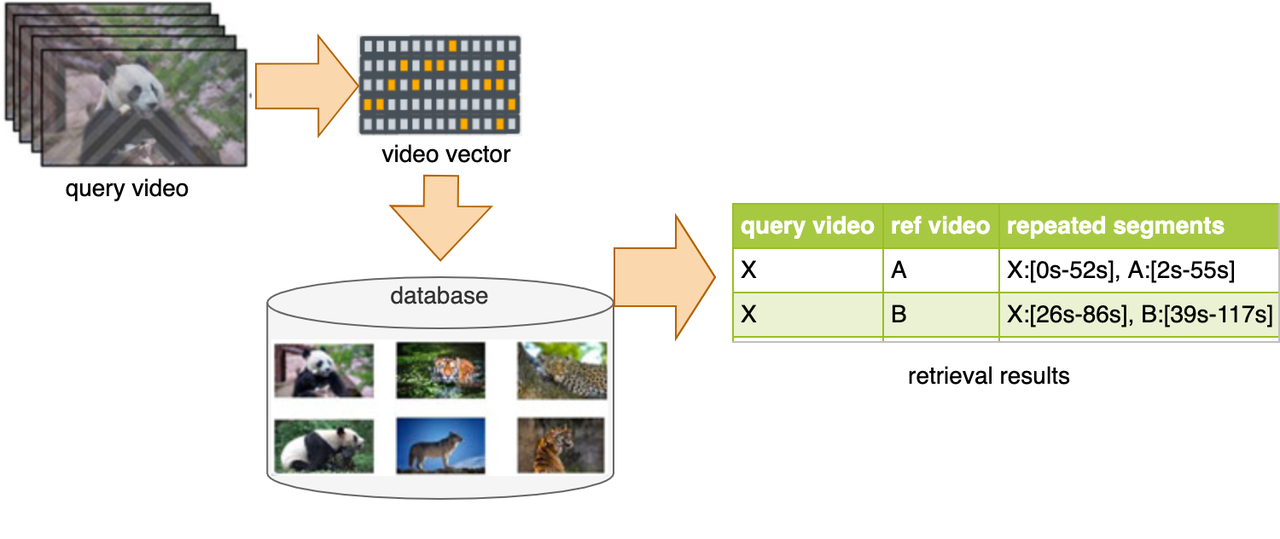
Video Copy Detection, also known as Video Identification by Fingerprinting, is to retrieve the similar or exact same video for a given query video.
Due to the popularity of Internet-based video sharing services, the volume of video content on the Internet has reached unprecedented scales. A video copy detection system is important in applications like video classification, tracking, filtering and recommendation, not to mention the field of copyright protection.
However, content-based video retrieval is particularly hard in practice, one needs to calculate the similarity between the given video and each and every video in a database to retrieve and rank similar ones based on relevance. Threfore, We hereby introduce Milvus and Towhee to help building a Video Deduplication System within several lines.
Image credit: created by zc277584121
|
Model(s) |
Dim |
Recall |
Precision |
F1 |
Model(s) from |
|---|
The evaluation is tested using the VCSL test data set, and the F1 value of the video clip is the most important evaluation standard, which is introduced in the VCSL paper. Due to some video links not working, we only downloaded most of the videos, not all of them.
In the video copy detection case, we follow the precedure:
Before running the following code, please make sure you have created a collection, for example, named video_deuplication, and the same dimensions(256) as the model you wish to use for generating embedding.
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
connections.connect(host='127.0.0.1', port='19530')
def create_milvus_collection(collection_name, dim):
if utility.has_collection(collection_name):
utility.drop_collection(collection_name)
fields = [
FieldSchema(name='id', dtype=DataType.INT64, descrition='the id of the embedding', is_primary=True, auto_id=True),
FieldSchema(name='path', dtype=DataType.VARCHAR, descrition='the path of the embedding', max_length=500),
FieldSchema(name='embedding', dtype=DataType.FLOAT_VECTOR, descrition='video embedding vectors', dim=dim)
]
schema = CollectionSchema(fields=fields, description='video dedup')
collection = Collection(name=collection_name, schema=schema)
index_params = {'metric_type': 'IP', 'index_type': "IVF_FLAT", 'params': {"nlist": 1}}
collection.create_index(field_name="embedding", index_params=index_params)
return collection
# Change dimension according to embedding models.
collection = create_milvus_collection('video_deduplication', 256)Also, if one chooses hbase as the kv database, do remember to start hbase and create table.
We can use built-in pipeline video_embedding to get video
embeddings and insert them into Milvus and the kv database. By default, we use
ISC, which is a well trained model aimed specifically at video
copy detection tasks, to generate embedding. For the choice of the kv
database, we support leveldb and hbase by passing
different args to the pipeline config.
from towhee import AutoPipes, AutoConfig
emb_conf = AutoConfig.load_config('video_embedding')
emb_conf.collection='video_copy_detections'
emb_conf.start_time = None
emb_conf.end_time = None
emb_conf.device = -1 # 0
# use leveldb
# emb_conf.leveldb_path = 'url_vec.db'
emb_conf.hbase_table='video_copy_detection'
emb_pipe = AutoPipes.pipeline('video_embedding', emb_conf)
for i in video_list:
result = emb_pipe(i)The embedding models we support are listed on performance.
Before searching in Milvus, you need to load the collection first.
from towhee import AutoPipes, AutoConfig
from towhee.datacollection import DataCollection
search_conf = AutoConfig.load_config('video_copy_detection')
search_conf.collection='video_copy_detection'
search_conf.start_time = None
search_conf.end_time = None
search_conf.device = -1 # 0
# use leveldb
# search_conf.leveldb_path = 'url_vec.db'
search_conf.hbase_table='video_copy_detection'
search_conf.threshold = 0.5
search_pipe = AutoPipes.pipeline('video_copy_detection', search_conf)
for i in video_list:
result = search_pipe(i)
DataCollection(res).show()name (str):
The name of the built-in pipeline, such as
video_embedding and video_copy_detection.
name: str
The name of the built-in pipeline, such as
video_embedding and video_copy_detection.
start_time: int = None:
The start of the range to decode.
end_time: int = None:
The end of the range to decode.
img_size: int = 512:
The input image size of isc model, reduce it to speed up isc embedding.
model: str = 'isc':
The embedding model.
milvus_host: str = '127.0.0.1'
The host of Milvus.
milvus_port: str = '19530'
The port of Milvus.
collection: str
The milvus collection name we want to insert embedding into it.
hbase_host: str = '127.0.0.1'
The host of hbase.
hbase_port: int = 9090
The port of hbase
hbase_table: str
The hbase table we want to store the KV in it.
leveldb_path: str
The path of the leveldb file.
device = -1
The device we run the pipeline, -1 for cpu, 0, 1, 2 … for gpus.
VideoCopyDetectionConfig
Apart from the above config in VideoEmbeddingConfig, VideoCopyDetectionConfig contains following config:
milvus_search_limit: int = 64
The number of embeddings returned from milvus search op
top_k: int = 5
The number of nearest videos to return by pipeline
min_similar_length: int = 1
The minimal similar frame(s) that the return videos should contain.
Threshold: float = None:
Filter the videos whose similarity is less than the threshold.