# Image-Text Retrieval Embdding with BLIP
*author: David Wang*
## Description
This operator extracts features for image or text with [BLIP](https://arxiv.org/abs/2201.12086) which can generate embeddings for text and image by jointly training an image encoder and text encoder to maximize the cosine similarity. This is a adaptation from [salesforce/BLIP](https://github.com/salesforce/BLIP).
## Code Example
Load an image from path './teddy.jpg' to generate an image embedding.
Read the text 'A teddybear on a skateboard in Times Square.' to generate an text embedding.
*Write the pipeline in simplified style*:
```python
import towhee
towhee.glob('./teddy.jpg') \
.image_decode() \
.image_text_embedding.blip(model_name='blip_base', modality='image') \
.show()
towhee.dc(["A teddybear on a skateboard in Times Square."]) \
.image_text_embedding.blip(model_name='blip_base', modality='text') \
.show()
```
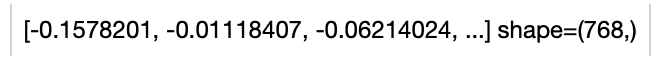
 *Write a same pipeline with explicit inputs/outputs name specifications:*
```python
import towhee
towhee.glob['path']('./teddy.jpg') \
.image_decode['path', 'img']() \
.image_text_embedding.blip['img', 'vec'](model_name='blip_base', modality='image') \
.select['img', 'vec']() \
.show()
towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
.image_text_embedding.blip['text','vec'](model_name='blip_base', modality='text') \
.select['text', 'vec']() \
.show()
```
*Write a same pipeline with explicit inputs/outputs name specifications:*
```python
import towhee
towhee.glob['path']('./teddy.jpg') \
.image_decode['path', 'img']() \
.image_text_embedding.blip['img', 'vec'](model_name='blip_base', modality='image') \
.select['img', 'vec']() \
.show()
towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
.image_text_embedding.blip['text','vec'](model_name='blip_base', modality='text') \
.select['text', 'vec']() \
.show()
```


## Factory Constructor
Create the operator via the following factory method
***blip(model_name, modality)***
**Parameters:**
***model_name:*** *str*
The model name of BLIP. Supported model names:
- blip_base
***modality:*** *str*
Which modality(*image* or *text*) is used to generate the embedding.
## Interface
An image-text embedding operator takes a [towhee image](link/to/towhee/image/api/doc) or string as input and generate an embedding in ndarray.
**Parameters:**
***data:*** *towhee.types.Image (a sub-class of numpy.ndarray)* or *str*
The data (image or text based on specified modality) to generate embedding.
**Returns:** *numpy.ndarray*
The data embedding extracted by model.
# More Resources
- [CLIP Object Detection: Merging AI Vision with Language Understanding - Zilliz blog](https://zilliz.com/learn/CLIP-object-detection-merge-AI-vision-with-language-understanding): CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.
- [Supercharged Semantic Similarity Search in Production - Zilliz blog](https://zilliz.com/learn/supercharged-semantic-similarity-search-in-production): Building a Blazing Fast, Highly Scalable Text-to-Image Search with CLIP embeddings and Milvus, the most advanced open-source vector database.
- [Hybrid Search: Combining Text and Image for Enhanced Search Capabilities - Zilliz blog](https://zilliz.com/learn/hybrid-search-combining-text-and-image): Milvus enables hybrid sparse and dense vector search and multi-vector search capabilities, simplifying the vectorization and search process.
- [The guide to all-MiniLM-L12-v2 | Hugging Face](https://zilliz.com/ai-models/all-MiniLM-L12-v2): all-MiniLM-L12-v2: a text embedding model ideal for semantic search and RAG and fine-tuned based on Microsoft/MiniLM-L12-H384-uncased
- [An LLM Powered Text to Image Prompt Generation with Milvus - Zilliz blog](https://zilliz.com/blog/llm-powered-text-to-image-prompt-generation-with-milvus): An interesting LLM project powered by the Milvus vector database for generating more efficient text-to-image prompts.
- [Build a Multimodal Search System with Milvus - Zilliz blog](https://zilliz.com/blog/how-vector-dbs-are-revolutionizing-unstructured-data-search-ai-applications): Implementing a Multimodal Similarity Search System Using Milvus, Radient, ImageBind, and Meta-Chameleon-7b
- [Enhancing Efficiency in Vector Searches with Binary Quantization and Milvus - Zilliz blog](https://zilliz.com/learn/enhancing-efficiency-in-vector-searches-with-binary-quantization-and-milvus): Binary quantization represents a transformative approach to managing and searching vector data within Milvus, offering significant enhancements in both performance and efficiency. By simplifying vector representations into binary codes, this method leverages the speed of bitwise operations, substantially accelerating search operations and reducing computational overhead.
- [Image Embeddings for Enhanced Image Search - Zilliz blog](https://zilliz.com/learn/image-embeddings-for-enhanced-image-search): Image Embeddings are the core of modern computer vision algorithms. Understand their implementation and use cases and explore different image embedding models.