
Readme
Files and versions
4.1 KiB
Image-Text Retrieval Embdding with CLIP
author: David Wang
Description
This operator extracts features for image or text with CLIP which can generate embeddings for text and image by jointly training an image encoder and text encoder to maximize the cosine similarity.
Code Example
Load an image from path './teddy.jpg' to generate an image embedding.
Read the text 'A teddybear on a skateboard in Times Square.' to generate an text embedding.
Write the pipeline in simplified style:
import towhee
towhee.glob('./teddy.jpg') \
.image_decode() \
.towhee.clip(model_name='clip_vit_b32', modality='image') \
.show()
towhee.dc(["A teddybear on a skateboard in Times Square."]) \
.towhee.clip(model_name='clip_vit_b32', modality='text') \
.show()
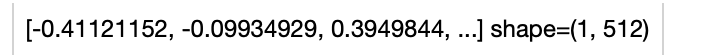
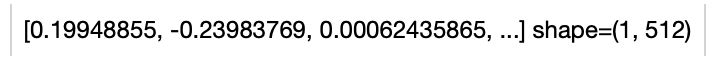
Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
towhee.glob['path']('./teddy.jpg') \
.image_decode['path', 'img']() \
.towhee.clip['img', 'vec'](model_name='clip_vit_b32', modality='image') \
.select['img', 'vec']() \
.show()
towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
.towhee.clip['text','vec'](model_name='clip_vit_b32', modality='text') \
.select['text', 'vec']() \
.show()


Factory Constructor
Create the operator via the following factory method
clip(model_name, modality)
Parameters:
model_name: str
The model name of CLIP. Supported model names:
- clip_resnet_r50
- clip_resnet_r101
- clip_vit_b32
- clip_vit_b16
modality: str
Which modality(image or text) is used to generate the embedding.
Interface
An image-text embedding operator takes a towhee image or string as input and generate an embedding in ndarray.
Parameters:
data: towhee.types.Image (a sub-class of numpy.ndarray) or str
The data (image or text based on specified modality) to generate embedding.
Returns: numpy.ndarray
The data embedding extracted by model.
More Resources
- CLIP Object Detection: Merging AI Vision with Language Understanding - Zilliz blog: CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.
- Supercharged Semantic Similarity Search in Production - Zilliz blog: Building a Blazing Fast, Highly Scalable Text-to-Image Search with CLIP embeddings and Milvus, the most advanced open-source vector database.
- The guide to clip-vit-base-patch32 | OpenAI: clip-vit-base-patch32: a CLIP multimodal model variant by OpenAI for image and text embedding.
- Image Embeddings for Enhanced Image Search - Zilliz blog: Image Embeddings are the core of modern computer vision algorithms. Understand their implementation and use cases and explore different image embedding models.
- From Text to Image: Fundamentals of CLIP - Zilliz blog: Search algorithms rely on semantic similarity to retrieve the most relevant results. With the CLIP model, the semantics of texts and images can be connected in a high-dimensional vector space. Read this simple introduction to see how CLIP can help you build a powerful text-to-image service.
4.1 KiB
Image-Text Retrieval Embdding with CLIP
author: David Wang
Description
This operator extracts features for image or text with CLIP which can generate embeddings for text and image by jointly training an image encoder and text encoder to maximize the cosine similarity.
Code Example
Load an image from path './teddy.jpg' to generate an image embedding.
Read the text 'A teddybear on a skateboard in Times Square.' to generate an text embedding.
Write the pipeline in simplified style:
import towhee
towhee.glob('./teddy.jpg') \
.image_decode() \
.towhee.clip(model_name='clip_vit_b32', modality='image') \
.show()
towhee.dc(["A teddybear on a skateboard in Times Square."]) \
.towhee.clip(model_name='clip_vit_b32', modality='text') \
.show()
Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
towhee.glob['path']('./teddy.jpg') \
.image_decode['path', 'img']() \
.towhee.clip['img', 'vec'](model_name='clip_vit_b32', modality='image') \
.select['img', 'vec']() \
.show()
towhee.dc['text'](["A teddybear on a skateboard in Times Square."]) \
.towhee.clip['text','vec'](model_name='clip_vit_b32', modality='text') \
.select['text', 'vec']() \
.show()
Factory Constructor
Create the operator via the following factory method
clip(model_name, modality)
Parameters:
model_name: str
The model name of CLIP. Supported model names:
- clip_resnet_r50
- clip_resnet_r101
- clip_vit_b32
- clip_vit_b16
modality: str
Which modality(image or text) is used to generate the embedding.
Interface
An image-text embedding operator takes a towhee image or string as input and generate an embedding in ndarray.
Parameters:
data: towhee.types.Image (a sub-class of numpy.ndarray) or str
The data (image or text based on specified modality) to generate embedding.
Returns: numpy.ndarray
The data embedding extracted by model.
More Resources
- CLIP Object Detection: Merging AI Vision with Language Understanding - Zilliz blog: CLIP Object Detection combines CLIP's text-image understanding with object detection tasks, allowing CLIP to locate and identify objects in images using texts.
- Supercharged Semantic Similarity Search in Production - Zilliz blog: Building a Blazing Fast, Highly Scalable Text-to-Image Search with CLIP embeddings and Milvus, the most advanced open-source vector database.
- The guide to clip-vit-base-patch32 | OpenAI: clip-vit-base-patch32: a CLIP multimodal model variant by OpenAI for image and text embedding.
- Image Embeddings for Enhanced Image Search - Zilliz blog: Image Embeddings are the core of modern computer vision algorithms. Understand their implementation and use cases and explore different image embedding models.
- From Text to Image: Fundamentals of CLIP - Zilliz blog: Search algorithms rely on semantic similarity to retrieve the most relevant results. With the CLIP model, the semantics of texts and images can be connected in a high-dimensional vector space. Read this simple introduction to see how CLIP can help you build a powerful text-to-image service.