
Readme
Files and versions
2.3 KiB
Image-Text Retrieval Embdding with CLIP
author: David Wang
Description
This operator extracts features for image or text with CLIP which can genearte the embedding for text and image by jointly training an image encoder and text encoder to maximize the cosine similarity. This operator is an adaptation from openai/CLIP.
Code Example
Load an image from path './teddy.jpg' to generate an image embedding. Read the text 'a dog' to generate an text embedding. Write the pipeline in simplified style:
import towhee
towhee.glob('./dog.jpg') \
.image_decode.cv2() \
.towhee.clip(name='ViT-B/32', modality='image') \
.show()
towhee.dc(["a dog"]) \
.image_decode.cv2() \
.towhee.clip(name='ViT-B/32', modality='text') \
.show()
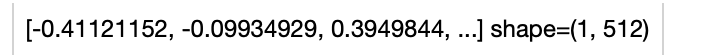
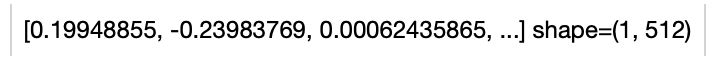
Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
towhee.glob['path']('./dog.jpg') \
.image_decode.cv2['path', 'img']() \
.towhee.clip['data', 'vec'](name='ViT-B/32', modality='image') \
.select['data', 'vec']() \
.show()
towhee.dc(["a dog"]) \
.select['img', 'vec']() \
.towhee.clip['data', 'vec'](name='ViT-B/32', modality='image') \
.select['data', 'vec']() \
.show()

Factory Constructor
Create the operator via the following factory method
clip(name, modality)
Parameters:
name: str
The model name of CLIP.
modality: str
Which modality(image or text) is used to generate the embedding.
Interface
An image-text embedding operator takes a towhee image or string as input and generate an image embedding in ndarray.
Parameters:
data: towhee.types.Image (a sub-class of numpy.ndarray) or str
The data(image or text based on choosed modality) to generate the embedding.
Returns: numpy.ndarray
The data embedding extracted by model.
2.3 KiB
Image-Text Retrieval Embdding with CLIP
author: David Wang
Description
This operator extracts features for image or text with CLIP which can genearte the embedding for text and image by jointly training an image encoder and text encoder to maximize the cosine similarity. This operator is an adaptation from openai/CLIP.
Code Example
Load an image from path './teddy.jpg' to generate an image embedding. Read the text 'a dog' to generate an text embedding. Write the pipeline in simplified style:
import towhee
towhee.glob('./dog.jpg') \
.image_decode.cv2() \
.towhee.clip(name='ViT-B/32', modality='image') \
.show()
towhee.dc(["a dog"]) \
.image_decode.cv2() \
.towhee.clip(name='ViT-B/32', modality='text') \
.show()
Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
towhee.glob['path']('./dog.jpg') \
.image_decode.cv2['path', 'img']() \
.towhee.clip['data', 'vec'](name='ViT-B/32', modality='image') \
.select['data', 'vec']() \
.show()
towhee.dc(["a dog"]) \
.select['img', 'vec']() \
.towhee.clip['data', 'vec'](name='ViT-B/32', modality='image') \
.select['data', 'vec']() \
.show()
Factory Constructor
Create the operator via the following factory method
clip(name, modality)
Parameters:
name: str
The model name of CLIP.
modality: str
Which modality(image or text) is used to generate the embedding.
Interface
An image-text embedding operator takes a towhee image or string as input and generate an image embedding in ndarray.
Parameters:
data: towhee.types.Image (a sub-class of numpy.ndarray) or str
The data(image or text based on choosed modality) to generate the embedding.
Returns: numpy.ndarray
The data embedding extracted by model.