# Text Loader
*author: shiyu22*
### Description
**Text Loader** is used to load the documents and split it to a list of text.
**Text loader** is used to load files and split them into text lists. It supports loading local files (with file path), or web links (with url).
> Refer to [Recursive Characters](https://python.langchain.com/en/latest/modules/indexes/text_splitters/examples/recursive_text_splitter.html) for the operation of splitting text.
### Code Example
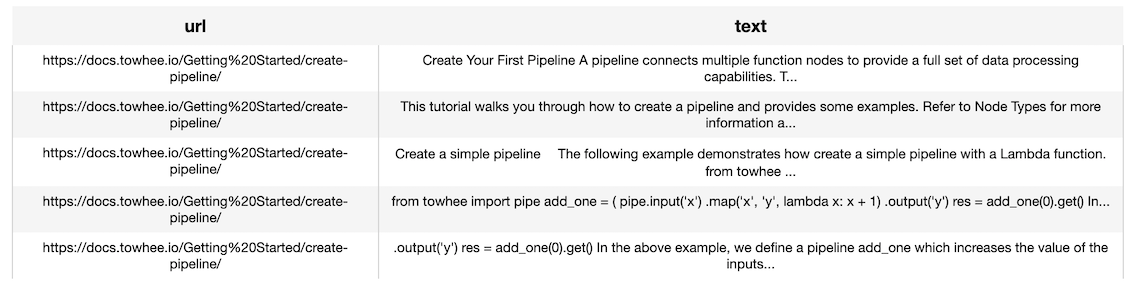
Writing the pipeline in the simplified way
```Python
from towhee import pipe, ops, DataCollection
p = (
pipe.input('url')
.flat_map('url', 'text', ops.text_loader(source_type='url'))
.output('url', 'text')
)
res = p('https://docs.towhee.io/Getting%20Started/create-pipeline/')
DataCollection(res).show()
```
## Factory Constructor
Create the operator via the following factory method
***towhee.text_loader(chunk_size=300, source_type='file')***
### Interface
The operator load the documentation, then split incoming the text and return chunks.
**Parameters:**
***chunk_size***: int
The size of each chunk, defaults to 300.
***source_type***: str
The type of the soure, defaults to 'file', you can also set to 'url' for you url of your documentation.
**Return**: List[Document]
A list of the chunked document.