
copied
Readme
Files and versions
Updated 4 years ago
video-text-embedding
Video-Text Retrieval Embdding with MDMMT
author: Chen Zhang
Description
This operator extracts features for video or text with MDMMT: Multidomain Multimodal Transformer for Video Retrieval, which can generate embeddings for text and video by jointly training a video encoder and text encoder to maximize the cosine similarity.
Code Example
Load a video embeddings extracted from different upstream expert networks, such as video, RGB, audio.
Read the text to generate a text embedding.
Write the pipeline code:
import towhee
import torch
torch.manual_seed(42)
# features are embeddings extracted from the upstream models.
features = {
"VIDEO": torch.rand(30, 2048),
"CLIP": torch.rand(30, 512),
"tf_vggish": torch.rand(30, 128),
}
# features_t is the time series of the features, usually uniformly sampled.
features_t = {
"VIDEO": torch.linspace(1, 30, steps=30),
"CLIP": torch.linspace(1, 30, steps=30),
"tf_vggish": torch.linspace(1, 30, steps=30),
}
# features_ind is the mask of the features.
features_ind = {
"VIDEO": torch.as_tensor([1] * 25 + [0] * 5),
"CLIP": torch.as_tensor([1] * 25 + [0] * 5),
"tf_vggish": torch.as_tensor([1] * 25 + [0] * 5),
}
video_input_dict = {"features": features, "features_t": features_t, "features_ind": features_ind}
towhee.dc([video_input_dict]).video_text_embedding.mdmmt(modality='video', device='cpu').show()
towhee.dc(['Hello world.']).video_text_embedding.mdmmt(modality='text', device='cpu').show()
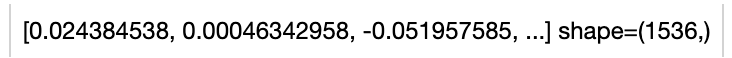

Write a same pipeline with explicit inputs/outputs name specifications:
Factory Constructor
Create the operator via the following factory method
mdmmt(modality: str)
Parameters:
modality: str
Which modality(video or text) is used to generate the embedding.
weight_path: Optional[str]
pretrained model weights path.
device: Optional[str]
cpu or cuda.
mmtvid_params: Optional[dict]
mmtvid model params for custom model.
mmttxt_params: Optional[dict]
mmttxt model params for custom model.
Interface
When video modality, load a video embeddings extracted from different upstream expert networks, such as video, RGB, audio.
When text modality, read the text to generate a text embedding.
Parameters:
data: dict or str
The embedding dict extracted from different upstream expert networks or text, based on specified modality).
Returns: numpy.ndarray
The data embedding extracted by model.
|
| 2 Commits | ||
|---|---|---|---|
 .gitattributes
.gitattributes
|
1.1 KiB
|
4 years ago | |
|
README.md
|
2.7 KiB
|
4 years ago | |
|
__init__.py
|
694 B
|
4 years ago | |
|
mdmmt.py
|
5.4 KiB
|
4 years ago | |
|
requirements.txt
|
39 B
|
4 years ago | |
|
vect_simplified_text.png
|
7.3 KiB
|
4 years ago | |
|
vect_simplified_video.png
|
7.6 KiB
|
4 years ago | |
{kind=link}
{kind=link}