
copied
Readme
Files and versions
Updated 4 years ago
image-text-embedding
Image-Text Retrieval Embdding with SLIP
author: David Wang
Description
This operator extracts features for image or text with SLIP, a multi-task learning framework for combining self-supervised learning and CLIP pre-training. This is an adaptation from facebookresearch/SLIP.
Code Example
Load an image from path './teddy.jpg' to generate an image embedding.
Read the text 'A teddybear on a skateboard in Times Square.' to generate an text embedding.
Write the pipeline in simplified style:
import towhee
towhee.glob('./moon.jpeg') \
.image_decode() \
.image_text_embedding.slip(model_name='slip_vit_small', modality='image') \
.show()
towhee.dc(['moon in the night.']) \
.image_text_embedding.slip(model_name='slip_vit_small', modality='text') \
.show()
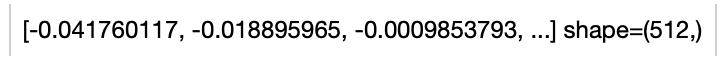
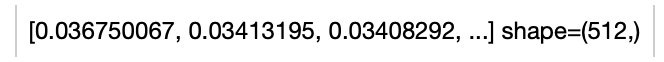
Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
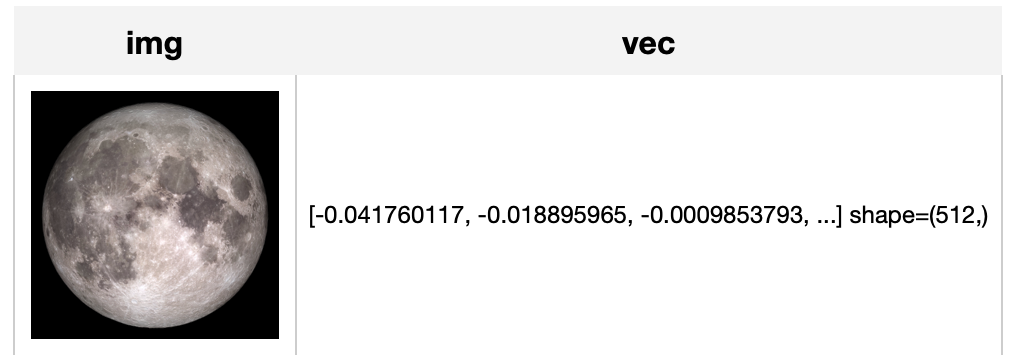
towhee.glob['path']('./moon.jpeg') \
.image_decode['path', 'img']() \
.image_text_embedding.slip['img', 'vec'](model_name='slip_vit_small', modality='image') \
.select['img', 'vec']() \
.show()
towhee.dc['text'](['moon in the night.']) \
.image_text_embedding.slip['text','vec'](model_name= 'slip_vit_small', modality='text') \
.select['text', 'vec']() \
.show()

Factory Constructor
Create the operator via the following factory method
slip(model_name, modality)
Parameters:
model_name: str
The model name of SLIP. Supported model names:
- slip_vit_small
- slip_vit_base
- slip_vit_large
modality: str
Which modality(image or text) is used to generate the embedding.
Interface
An image-text embedding operator takes a towhee image or string as input and generate an embedding in ndarray.
Parameters:
data: towhee.types.Image (a sub-class of numpy.ndarray) or str
The data (image or text based on specified modality) to generate embedding.
Returns: numpy.ndarray
The data embedding extracted by model.
|
| 4 Commits | ||
|---|---|---|---|
 .gitattributes
.gitattributes
|
1.1 KiB
|
4 years ago | |
|
README.md
|
2.4 KiB
|
4 years ago | |
|
__init__.py
|
698 B
|
4 years ago | |
|
bpe_simple_vocab_16e6.txt.gz
|
1.3 MiB
|
4 years ago | |
|
models.py
|
11 KiB
|
4 years ago | |
|
requirements.txt
|
54 B
|
4 years ago | |
|
slip.py
|
4.9 KiB
|
4 years ago | |
|
tabular1.png
|
120 KiB
|
4 years ago | |
|
tabular2.png
|
16 KiB

|
4 years ago | |
|
tokenizer.py
|
5.4 KiB
|
4 years ago | |
|
vec1.png
|
10 KiB
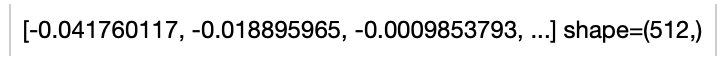
|
4 years ago | |
|
vec2.png
|
10 KiB
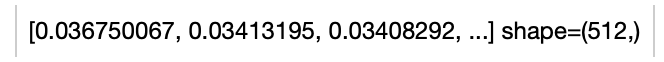
|
4 years ago | |
{kind=link}
{kind=link}
{kind=link}
{kind=link}