
copied
Readme
Files and versions
Updated 4 years ago
video-text-embedding
Video-Text Retrieval Embdding with CLIP4Clip
author: Chen Zhang
Description
This operator extracts features for video or text with CLIP4Clip which can generate embeddings for text and video by jointly training a video encoder and text encoder to maximize the cosine similarity.
Code Example
Load an video from path './demo_video.mp4' to generate an video embedding.
Read the text 'kids feeding and playing with the horse' to generate an text embedding.
Write the pipeline in simplified style:
import towhee
towhee.dc(['./demo_video.mp4']) \
.video_decode.ffmpeg(sample_type='uniform_temporal_subsample', args={'num_samples': 12}) \
.runas_op(func=lambda x: [y for y in x]) \
.clip4clip(model_name='clip_vit_b32', modality='video', weight_path='./pytorch_model.bin.1', device='cpu') \
.show()
towhee.dc(['kids feeding and playing with the horse']) \
.clip4clip(model_name='clip_vit_b32', modality='text', weight_path='./pytorch_model.bin.1', device='cpu') \
.show()
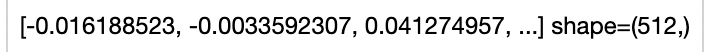
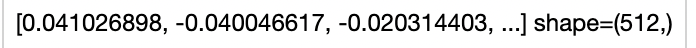
Write a same pipeline with explicit inputs/outputs name specifications:
import towhee
towhee.dc['path'](['./demo_video.mp4']) \
.video_decode.ffmpeg['path', 'frames'](sample_type='uniform_temporal_subsample', args={'num_samples': 12}) \
.runas_op['frames', 'frames'](func=lambda x: [y for y in x]) \
.clip4clip['frames', 'vec'](model_name='clip_vit_b32', modality='video', weight_path='./pytorch_model.bin.1', device='cpu') \
.show()
towhee.dc['text'](["kids feeding and playing with the horse"]) \
.clip4clip['text','vec'](model_name='clip_vit_b32', modality='text', weight_path='./pytorch_model.bin.1', device='cpu') \
.select['text', 'vec']() \
.show()


Factory Constructor
Create the operator via the following factory method
clip4clip(model_name, modality, weight_path)
Parameters:
model_name: str
The model name of CLIP. Supported model names:
- clip_vit_b32
modality: str
Which modality(video or text) is used to generate the embedding.
weight_path: str
pretrained model weights path.
Interface
An video-text embedding operator takes a list of towhee image or string as input and generate an embedding in ndarray.
Parameters:
data: List[towhee.types.Image] or str
The data (list of image(which is uniform subsampled from a video) or text based on specified modality) to generate embedding.
Returns: numpy.ndarray
The data embedding extracted by model.
|
| 8 Commits | ||
|---|---|---|---|
 .gitattributes
.gitattributes
|
1.1 KiB
|
4 years ago | |
|
README.md
|
2.8 KiB
|
4 years ago | |
|
__init__.py
|
771 B
|
4 years ago | |
|
clip4clip.py
|
4.5 KiB
|
4 years ago | |
|
demo_video.mp4
|
950 KiB
|
4 years ago | |
|
pytorch_model.bin.1
|
337 MiB
|
4 years ago | |
|
requirements.txt
|
0 B
|
4 years ago | |
|
vect_explicit_text.png
|
36 KiB

|
4 years ago | |
|
vect_explicit_video.png
|
36 KiB

|
4 years ago | |
|
vect_simplified_text.png
|
17 KiB
|
4 years ago | |
|
vect_simplified_video.png
|
18 KiB
|
4 years ago | |
{kind=link}
{kind=link}
{kind=link}
{kind=link}