
copied
Readme
Files and versions
Updated 2 years ago
video-text-embedding
Video-Text Retrieval Embedding with DRL
author: Chen Zhang
Description
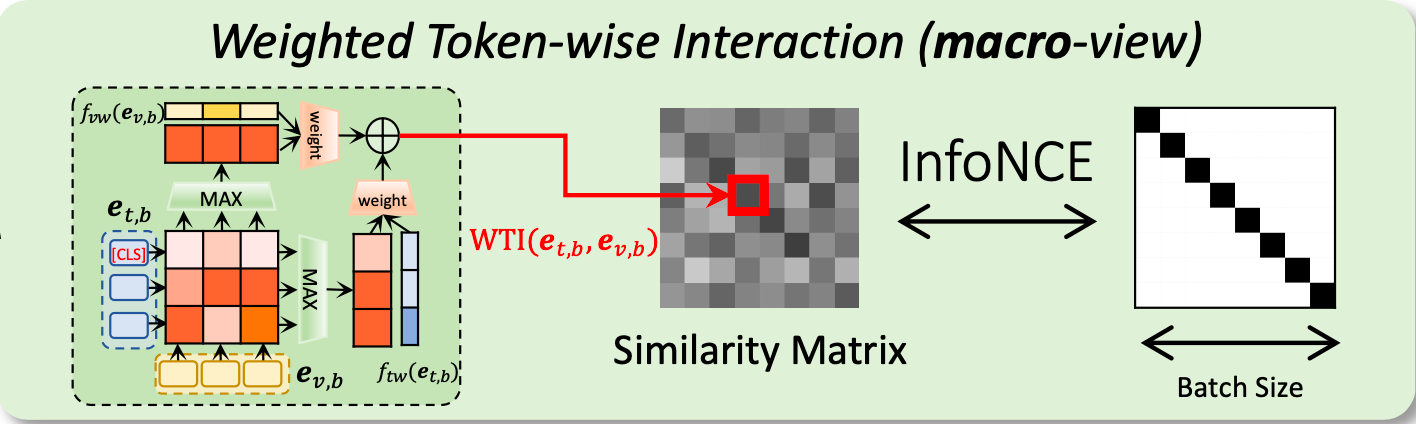
This operator extracts features for video or text with DRL(Disentangled Representation Learning for Text-Video Retrieval), and then it can get the similarity by Weighted Token-wise Interaction (WTI) module.
Code Example
Read the text 'kids feeding and playing with the horse' to generate a text embedding.
from towhee import pipe, ops, DataCollection
p = (
pipe.input('text') \
.map('text', 'vec', ops.video_text_embedding.drl(base_encoder='clip_vit_b32', modality='text', device='cuda:0')) \
.output('text', 'vec')
)
DataCollection(p('kids feeding and playing with the horse')).show()

Load an video from path './demo_video.mp4' to generate a video embedding.
from towhee import pipe, ops, DataCollection
p = (
pipe.input('video_path') \
.map('video_path', 'flame_gen', ops.video_decode.ffmpeg(sample_type='uniform_temporal_subsample', args={'num_samples': 12})) \
.map('flame_gen', 'flame_list', lambda x: [y for y in x]) \
.map('flame_list', 'vec', ops.video_text_embedding.drl(base_encoder='clip_vit_b32', modality='video', device='cuda:0')) \
.output('video_path', 'flame_list', 'vec')
)
DataCollection(p('./demo_video.mp4')).show()

Note: For this model, cpu is not support, and you must specify device='cuda...'
Factory Constructor
Create the operator via the following factory method
drl(base_encoder, modality)
Parameters:
base_encoder: str
The base CLIP encode name in DRL model. Supported model names:
- clip_vit_b32
modality: str
Which modality(video or text) is used to generate the embedding.
Interface
An video-text embedding operator takes a list of towhee VideoFrame or string as input and generate an embedding in ndarray.
Parameters:
data: List[towhee.types.VideoFrame] or str
The data (list of VideoFrame(which is uniform subsampled from a video) or text based on specified modality) to generate embedding.
Returns: numpy.ndarray
The data embedding extracted by model. When text, the shape is (text_token_num, model_dim), when video, the shape is (video_token_num, model_dim)
More Resources
- Vector Database Use Cases: Video Similarity Search - Zilliz: Experience a 10x performance boost and unparalleled precision when your video similarity search system is powered by Zilliz Cloud.
- ColBERT: A Token-Level Embedding and Ranking Model - Zilliz blog: Unlike traditional embedding models like BERT, which focus on pooling embeddings into a single vector, ColBERT retains individual token representations. Through its innovative late interaction mechanism, it enables more precise and granular similarity calculations.
- The guide to mistral-embed | Mistral AI: mistral-embed: a specialized embedding model for text data with a context window of 8,000 tokens. Optimized for similarity retrieval and RAG applications.
- Supercharged Semantic Similarity Search in Production - Zilliz blog: Building a Blazing Fast, Highly Scalable Text-to-Image Search with CLIP embeddings and Milvus, the most advanced open-source vector database.
- The guide to all-MiniLM-L12-v2 | Hugging Face: all-MiniLM-L12-v2: a text embedding model ideal for semantic search and RAG and fine-tuned based on Microsoft/MiniLM-L12-H384-uncased
- Build a Multimodal Search System with Milvus - Zilliz blog: Implementing a Multimodal Similarity Search System Using Milvus, Radient, ImageBind, and Meta-Chameleon-7b
- Sparse and Dense Embeddings: A Guide for Effective Information Retrieval with Milvus | Zilliz Webinar: Zilliz webinar covering what sparse and dense embeddings are and when you'd want to use one over the other.
- Sparse and Dense Embeddings: A Guide for Effective Information Retrieval with Milvus | Zilliz Webinar: Zilliz webinar covering what sparse and dense embeddings are and when you'd want to use one over the other.
- Training Text Embeddings with Jina AI - Zilliz blog: In a recent talk by Bo Wang, he discussed the creation of Jina text embeddings for modern vector search and RAG systems. He also shared methodologies for training embedding models that effectively encode extensive information, along with guidance o
|
| 10 Commits | ||
|---|---|---|---|
 .gitattributes
.gitattributes
|
1.2 KiB
|
4 years ago | |
|
README.md
|
5.1 KiB
|
2 years ago | |
|
WTI.png
|
82 KiB

|
4 years ago | |
|
__init__.py
|
719 B
|
4 years ago | |
|
clip_vit_b32_wti.pth
|
388 MiB
|
4 years ago | |
|
demo_video.mp4
|
950 KiB
|
4 years ago | |
|
drl.py
|
5.1 KiB
|
3 years ago | |
|
requirements.txt
|
58 B
|
4 years ago | |
|
text_emb_result.png
|
15 KiB

|
3 years ago | |
|
video_emb_result.png
|
30 KiB

|
3 years ago | |
{kind=link}
{kind=link}
{kind=link}